Kafka Streams is a Java library developed to help applications that do stream processing built on Kafka. To learn about Kafka Streams, you need to have a basic idea about Kafka to understand better. If you’ve worked with Kafka before, Kafka Streams is going to be easy to understand.
What are Kafka Streams?
Kafka Streams is a streaming application building library, specifically applications that turn Kafka input topics into Kafka output topics. Kafka Streams enables you to do this in a way that is distributed and fault-tolerant, with succinct code.
What is Stream processing?
Stream processing is the ongoing, concurrent, and record-by-record real-time processing of data.
Let us get started with some highlights of Kafka Streams:
- Low Barrier to Entry: Quickly write and run a small-scale POC on a single instance. You only need to run multiple instances of the application on various machines to scale up to high-volume production workloads.
- Lightweight and straightforward client library: Can be easily embedded in any Java application and integrated with any existing packaging, deployment, and operational tools.
- No external dependencies on systems other than Apache Kafka itself
- Fault-tolerant local state: Enables fast and efficient stateful operations like windowed joins and aggregations
- Supports exactly-once processing: Each record will be processed once and only once, even when there is a failure.
- One-record-at-a-time processing to achieve millisecond processing latency supports event-time-based windowing operations with out-of-order arrival of records.
Kafka Streams Concepts:
-
Stream: An ordered, replayable, and fault-tolerant sequence of immutable data records, where each data record is defined as a key-value pair.
-
Stream Processor: A node in the processor topology represents a processing step to transform data in streams by receiving one input record at a time from its source in the topology, applying any operation to it, and may subsequently produce one or more output records to its sinks.
There are two individual processors in the topology:
-
Source Processor: A source processor is a special type of stream processor that does not have any upstream processors. It produces an input stream to its topology from one or multiple Kafka topics by consuming records from these topics and forwarding them to its down-stream processors.
-
Sink Processor: A sink processor is a special type of stream processor that does not have down-stream processors. It sends any received records from its up-stream processors to a specified Kafka topic.
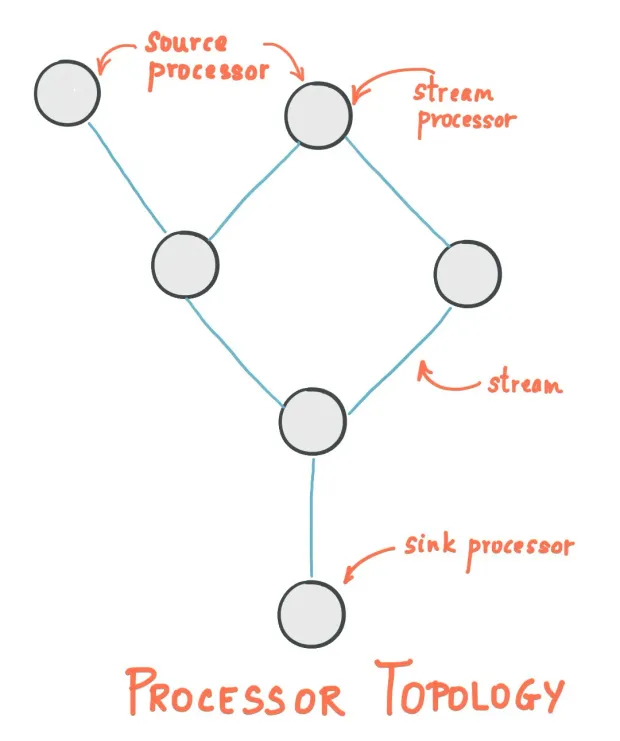
-
Kstream: KStream is nothing but that, a Kafka Stream. It’s a never-ending flow of data in a stream. Each piece of data — a record or a fact — is a collection of key-value pairs. Data records in a record stream are always interpreted as an "INSERT".
-
KTable: A KTable is just an abstraction of the stream, where only the latest value is kept. Data records in a record stream are always interpreted as an "UPDATE".
There is actually a close relationship between streams and tables, the so-called stream-table duality
Implementing Kafka Streams
Let's Start with the Setup using Scala instead of Java. The Kafka Streams DSL for Scala library is a wrapper over the existing Java APIs for Kafka Streams DSL.
To Setup things, we need to create a KafkaStreams Instance. It needs a topology and configuration (java.util.Properties). We also need a input topic and output topic. Let's look through a simple example of sending data from an input topic to an output topic using the Streams API
You can create a topic using the below commands (need to have Kafka pre installed)
1kafka-topics --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic inputTopic
2kafka-topics --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic outputTopic1val config: Properties = {
2 val properties = new Properties()
3 properties.put(StreamsConfig.APPLICATION_ID_CONFIG, "your-application")
4 properties.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092")
5 properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest")
6 properties.put(StreamsConfig.PROCESSING_GUARANTEE_CONFIG, StreamsConfig.EXACTLY_ONCE)
7 properties.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String())
8 properties.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String())
9 properties
10 }StreamsBuilder provide the high-level Kafka Streams DSL to specify a Kafka Streams topology.
1val builder: StreamsBuilder = new StreamsBuilderCreates a KStream from the specified topics.
1val inputStream: KStream[String,String] = builder.stream(inputTopic, Consumed.`with`(Serdes.String(), Serdes.String()))Store the input stream to the output topic.
1inputStream.to(outputTopic)(producedFromSerde(Serdes.String(),Serdes.String())Starts the Streams Application
1val kEventStream = new KafkaStreams(builder.build(), config)
2kEventStream.start()
3sys.ShutdownHookThread {
4 kEventStream.close(10, TimeUnit.SECONDS)
5 }You can send data to the input topic using
1kafka-console-producer --broker-list localhost:9092 --topic inputTopicAnd can fetch the data from the output topic using
1kafka-console-consumer --bootstrap-server localhost:9092 --topic outputTopic --from-beginningYou can add the necessary dependencies in your build file for sbt or pom file for maven. Below is an example for build.sbt.
1// Kafka
2libraryDependencies += "org.apache.kafka" %% "kafka-streams-scala" % "2.0.0"
3libraryDependencies += "javax.ws.rs" % "javax.ws.rs-api" % "2.1" artifacts( Artifact("javax.ws.rs-api", "jar", "jar")) // this is a workaround. There is an upstream dependency that causes trouble in SBT builds.Let us modify the code a little bit to try out a WordCount example: The code splits the sentences into words and groups by word as a key and the number of occurences or count as value and is being sent to the output topic by converting the KTable to KStream.
1val textLines: KStream[String, String] = builder.stream[String, String](inputTopic)
2val wordCounts: KTable[String, Long] = textLines
3 .flatMapValues(textLine => textLine.toLowerCase.split("\\W+"))
4 .groupBy((_, word) => word)
5 .count()(materializedFromSerde(Serdes.String(),Serdes.Long()))
6 wordCounts.toStream.to(outputTopic)(producedFromSerde(Serdes.String(),Serdes.Long())With the above process, we can now implement a simple streaming application or a word count application using Kafka Streams in Scala. If you want to set up kafka on Windows, here is a quick guide to implement apache kafka on windows OS.


