Most discussions around SCIM usually start with the protocol.
Ours didn’t.
It started with a very different problem - Enterprise customers of our B2B IAM users didn’t want to depend on support tickets to onboard and delete their end-users. Nor did they want to rely on manual access management systems, which often gave rise to the "we forgot to remove them" security incidents.
Many of them already had identity providers - Okta, Azure AD, OneLogin, etc. Users were created there, permissions were managed there, and deprovisioning had to happen there.
What our B2B IAM customers expected from us was straightforward - “When something changes in our customer’s IdP, your system should reflect it immediately.”
At first glance, this sounds like a standard integration problem.
But It wasn’t.
Because once you move into a B2B IAM model, you’re no longer syncing users into a single application. You’re syncing users into a multi-tenant identity system, where:
-
each organization is isolated
-
may of them have their own identity provider
-
and all of them expect strict correctness
We Experimented with Other Options
Before we implemented SCIM, we explored simpler approaches.
The most obvious one was:
-
allow organizations to upload users
-
or sync periodically via APIs
But that model started to break down almost immediately once we ran it against real enterprise environments.
The first issue we ran into was drift - and not the theoretical kind, but the kind that shows up quietly and then compounds over time.
For example, an user may be removed in the identity provider, but may continue to exist in our system. Nothing obviously “breaks” in that moment. The user record is still valid, sessions may still be active, and from the application’s perspective, everything looks normal.
But from a security perspective, it isn’t.
Now you have an identity that:
-
no longer exists in the system of record
-
but still has a footprint in your system
-
and potentially still has access
We initially tried to mitigate this with periodic synchronization. Poll the IdP, reconcile differences, clean things up.
That works in controlled environments.
But in practice, it introduces a window - sometimes minutes, sometimes longer - where your system is out of sync with the IdP. And in enterprise contexts, even a small window is enough to become a security concern.
At that point, it became clear that “eventual correctness” wasn’t sufficient. We needed immediacy and automation, not reconciliation.
SCIM Could Solve The Issues
At that point, adopting SCIM looked like the obvious next step.
On paper, it’s simple: a standard way to create, update, and deactivate users. It’s easy to assume this is just an API problem - expose a few endpoints, map them to your user model, and you’re done.
We started there.
And it worked for sometime, but then we hit an unexpected roadblock.
We realized SCIM doesn’t actually solve provisioning. It only standardizes how changes are sent to you. It doesn’t define how those changes should be applied, what happens when they arrive out of order, or how they behave in a multi-tenant system.
Those problems are still yours.
In our case, every request was:
-
externally triggered
-
asynchronous
-
scoped to a specific tenant
And none of them could be fully trusted to be:
-
ordered
-
unique
-
or complete
So the challenge wasn’t exposing endpoints like POST/Users or PATCH/Users/{id}.
It was building a system behind them that could accept unreliable external input, reconcile it with existing state, and apply it safely - without ever breaking tenant isolation or consistency.
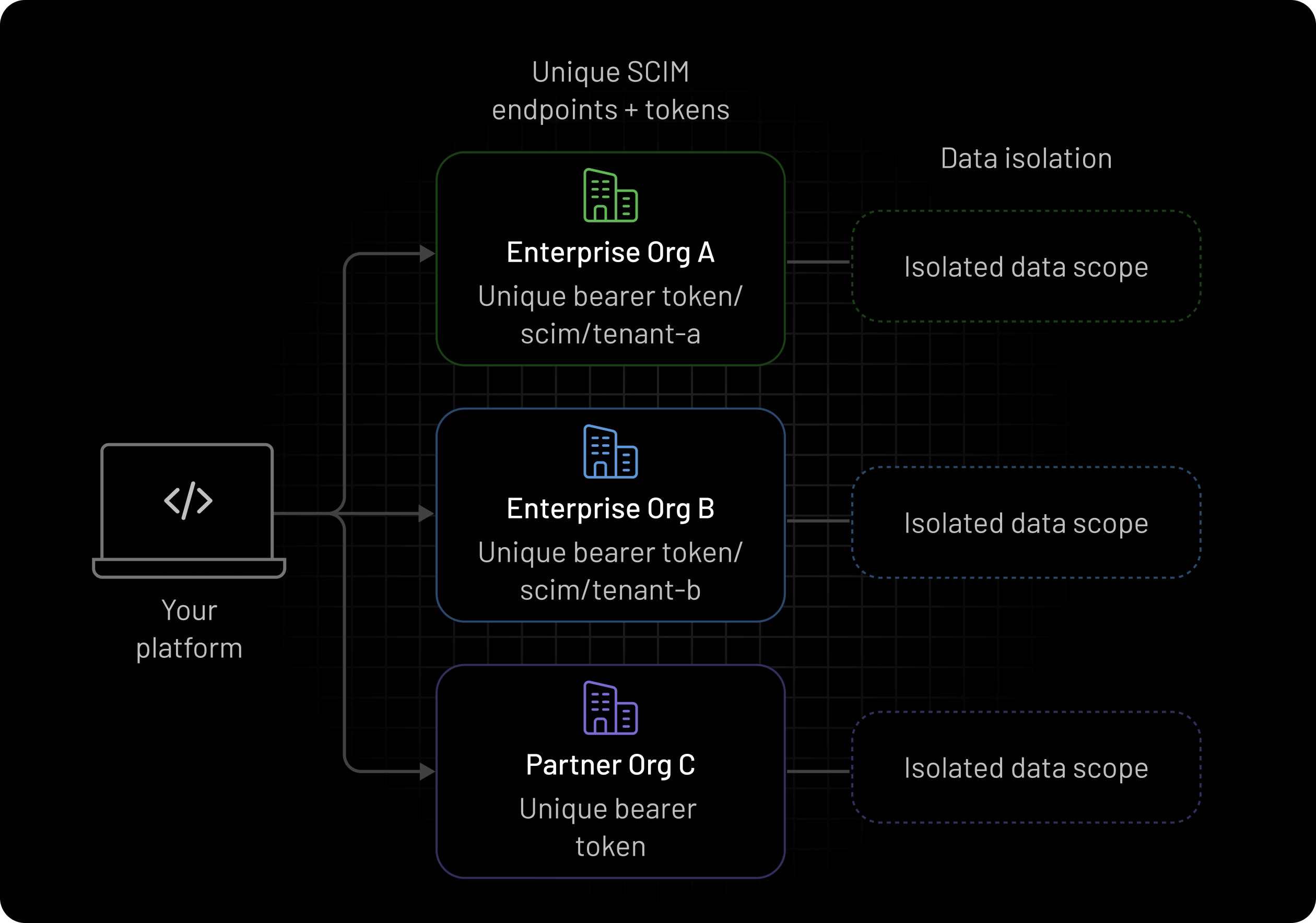
The First Real Constraint - Multi-Tenancy
In a single-tenant system, SCIM is relatively straightforward.
In a multi-tenant IAM system, every request must answer:
“Which organization does this belong to?”
At first, this doesn’t seem like a hard problem. The request payload already contains identifiers - user IDs, external references, sometimes even organization hints. It’s tempting to use those to determine where the request should go.
We tried that approach early on.
It didn’t take long to realize the problem.
Payload data is not a reliable source of truth. It can be:
-
inconsistent across requests
-
partially missing
-
or, in edge cases, intentionally manipulated
Using it to determine tenant context meant we were making routing decisions on data we didn’t fully control.
How We Solved it?
The fix was less about adding validation, and more about changing where the decision is made.
Instead of deriving tenant context from the request payload, we moved it to the authentication layer.
Every SCIM request is now:
-
authenticated with tenant-specific credentials
-
resolved to a tenant before it reaches provisioning logic
By the time the request is processed, its tenant context is already fixed and trusted.
Deprovisioning Was the Hardest Part
Provisioning users turned out to be the easy part.
Deprovisioning is where things got tricky—because this is exactly where the earlier drift problem shows up in its most critical form.
When a user is disabled or removed in the identity provider, the expectation is simple:
access should disappear immediately
But in practice, that change has multiple implications:
-
active sessions may still exist
-
cached permissions may still be valid
-
downstream systems may still treat the user as active
Nothing breaks instantly—but everything is now inconsistent.
The Consistency Tradeoff
We had to decide how far to push immediacy.
A fully synchronous model - where every downstream effect is completed before responding - sounds ideal, but introduces its own problems:
-
higher latency on provisioning calls
-
tighter coupling with dependent systems
-
and more failure points in the request path
On the other hand, delaying everything creates the same window we were trying to eliminate.
What We Landed On
We ended up splitting the problem into two parts.
The source of truth state is updated immediately:
- the user is marked inactive as soon as the SCIM request is processed
Everything else is treated as a side effect:
-
session invalidation
-
downstream updates
-
cleanup tasks
These run asynchronously, but in a controlled pipeline.
Why This Works
This gives us a clear guarantee:
the system state reflects the IdP immediately
While still allowing operational work to happen reliably in the background.
It also avoids reintroducing drift—because even if cleanup is delayed, the user is no longer considered active anywhere that matters.
Groups and Access Control
Users were only part of the problem.
In most enterprise environments, access isn’t assigned directly to users. It’s managed through groups—representing teams, roles, or organizational structure—and those groups are defined and maintained in the identity provider.
SCIM supports provisioning these groups, but it doesn’t define how they should translate into access within your system. That part is left entirely to the implementation.
We had to decide how tightly to couple external group structures with our authorization model.
Mapping groups directly to permissions sounds simple, but it assumes every organization structures access the same way. In practice, they don’t.
What we landed on was a model that keeps both sides clean.
Groups are provisioned via SCIM and can be mapped directly to roles defined within our system. This allows organizations to drive access using their existing group structures, without requiring per-user configuration.
At the same time, roles remain the enforcement layer.
This separation ensures that identity structure stays external, while access control remains consistent and predictable inside the system.
Failure Handling was a Concern
In most integrations, failures are treated as edge cases.
In SCIM provisioning, they’re part of normal operation.
Requests can fail for a variety of reasons:
-
incomplete or invalid payloads
-
schema mismatches
-
unexpected behavior from external identity providers
Trying to eliminate these failures entirely isn’t realistic.
Instead, we designed the system to handle them explicitly.
Every provisioning operation is tracked with:
-
clear failure states
-
reason codes
-
and retryability where applicable
Rather than failing silently or requiring manual investigation, each failure is:
-
visible
-
diagnosable
-
and recoverable
This becomes critical in real-world deployments, where debugging provisioning issues is not occasional—it’s continuous.
What Changed After We Built Directory Sync via SCIM Provisioning
Before implementing SCIM provisioning:
-
user management was partially manual
-
integrations were custom and inconsistent
-
and drift between systems was common
After implementing it:
-
identity updates became event-driven
-
organizations retained full control through their IdP
-
and user lifecycle management became predictable
But the bigger change was conceptual.
We stopped treating identity as something owned by the application.
Instead, it became:
externally managed, continuously synchronized state
That shift simplified the model for both us and our customers.
Closing Thought
SCIM doesn’t just standardize provisioning—it defines how your system stays in sync with your customers’ identity infrastructure.
Getting this right means no manual onboarding, no access drift, and no gaps between what exists in the IdP and what exists in your system. It’s what allows identity to flow reliably across tenants, workflows, and access layers.
That’s exactly what LoginRadius Directory Sync is built for.
It handles user and group provisioning end-to-end, keeps identities continuously aligned with external IdPs, and removes the operational overhead of managing users manually—all while maintaining strict tenant isolation and consistency.
Want to see how it works? Book a demo and we would be happy to give you a free walkthrough.


