When your webapp has a large amount of data to visualize, you don't want your users to wait 10 seconds before seeing something.
One technique that is often overlooked is HTTP streaming. It's broadly supported, works well, and doesn't require fancy libraries.
We're going to go through how we can use HTTP streaming in our applications and what to consider when we do so.
Introduction
When building web applications, we typically have a REST API with GET endpoints that do something like this:
- Parse the request (URL, query params, etc..)
- Query data from a database
- Convert the database results into JSON
- Send the JSON response back
The API will typically wait for each step to complete before going on to the next one, and by step 4, the database result and the JSON objects are all in memory before the request is handled, and everything can be cleaned up.
This works, and there is nothing wrong with it (KISS, right?) as long as your database query results are small and quickly available.
But let's say you want to render a chart with 10k data points. Querying will not be as smooth anymore. The simple way will work, but ideally, you don't want to accumulate all the data in memory before sending the response.
With HTTP streaming, you can start rendering the chart even before your query is complete.
To make it happen:
- Your API should use HTTP streaming to send its response.
- Your webapp should use the Fetch API to make the request so that it can process the streaming response.
Create a Streaming API
In this example, we use Koa for the API, but you can use other libraries like Express or plain Node.js. Most will have support for streaming.
Let's create an API:
1const Koa = require('koa');
2const app = new Koa();
3app.use(async (ctx) => {
4if (ctx.request.url === '/measurements.json') {
5ctx.response.set('content-type', 'application/json');
6// This is where the magic happens: set a stream as the response body
7ctx.body = fs.createReadStream('./measurements.json');
8}
9});
10http.createServer(app.callback()).listen(3000);This code creates an API with 1 endpoint GET /measurements that will respond with the contents of a JSON file with 10k measurements.
The file looks like this:
1[
2 { "id": "1", "timestamp": "2022-01-19T10:39:00.000Z", "value": 239.34 },
3 { "id": "2", "timestamp": "2022-01-19T10:40:00.000Z", "value": 820.14 },
4 { "id": "3", "timestamp": "2022-01-19T10:41:00.000Z", "value": 926.03 },
5 { "id": "4", "timestamp": "2022-01-19T10:42:00.000Z", "value": 513.01 },
6 // ...
7 { "id": "99998", "timestamp": "2022-03-29T21:16:00.000Z", "value": 13.81 },
8 { "id": "99999", "timestamp": "2022-03-29T21:17:00.000Z", "value": 465.28 },
9 { "id": "100000", "timestamp": "2022-03-29T21:18:00.000Z", "value": 71.95 }
10]We're creating an HTTP/1.1 server with Node's http module. By setting ctx.body to a stream, data will be sent to the requester as soon as it is loaded using a mechanism called chunked transfer encoding.
This saves time and memory of your API because it doesn't have to accumulate the whole result in memory before sending the response.
In a real application, you're probably using a database instead of a pre-created JSON file.
If you're using MongoDB, you can create a stream with the cursor's stream() method.
Consume a Streaming API From a Webapp
The GET /measurements endpoint we created can be consumed with any HTTP client, but you have to use the Fetch API to take advantage of streaming.
fetch() will set response.body to a ReadableStream for streaming responses.
Here's how you can read a streaming response:
1fetch('http://localhost:3000/measurements.json')
2 .then(async (response) => {
3 // response.body is a ReadableStream
4 const reader = response.body.getReader();
5 for await (const chunk of readChunks(reader)) {
6 console.log(`received chunk of size ${chunk.length}`);
7 }
8 });
9// readChunks() reads from the provided reader and yields the results into an async iterable
10function readChunks(reader) {
11return {
12async* Symbol.asyncIterator {
13let readResult = await reader.read();
14while (!readResult.done) {
15yield readResult.value;
16readResult = await reader.read();
17}
18},
19};
20}If you run the API that we created and then run the code above in a web browser, you'll see received chunk of size x several times in the console with varying x:
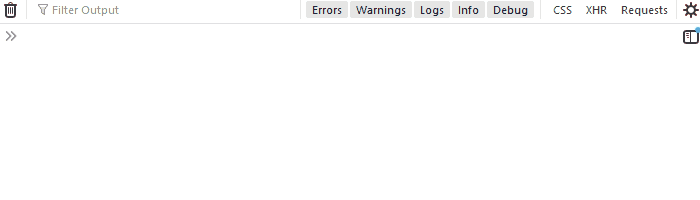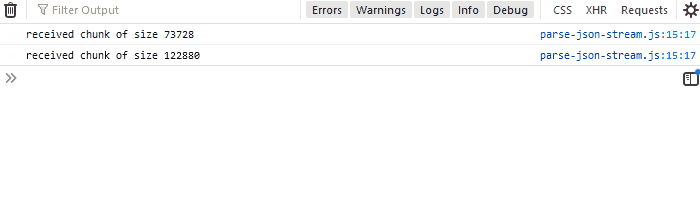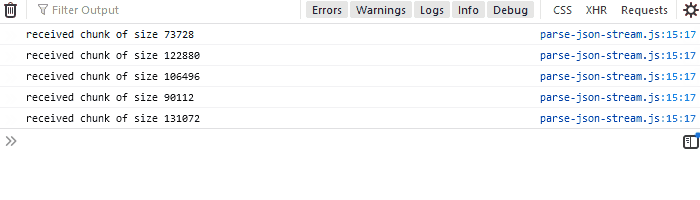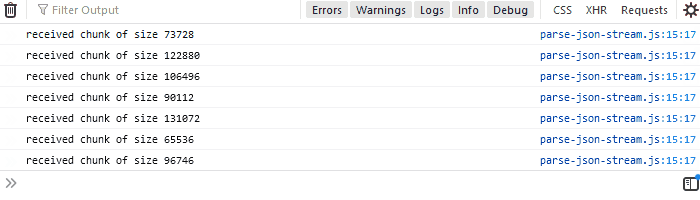
To see it more clearly, open up Developer Tools (F12) and set network throttling to 3G. It will take longer for the file to download, so you can see that the chunks are being processed gradually.
That's all very nice, but the chunks themselves are not very useful. You want to process the measurements that are in these chunks. Ideally, you would have an async iterable that gradually yields the JSON objects as they come in so that you can use for await to iterate over the measurements instead of the chunks.
JavaScript doesn't have a JSON parser that can deal with streams. Let's assume we have a function that can do this called parseJsonStream(readableStream). More details and a simple implementation can be found in "Streaming Considerations" below.
We would then be able to do this:
1fetch('http://localhost:3000/measurements.json')
2 .then(async (response) => {
3 let measurementsReceived = 0;
4 for await (const measurement of parseJsonStream(response.body)) {
5 measurementsReceived++;
6 // To prevent the console from flooding we only show 1 in every 100 measurements
7 if (measurementsReceived % 100 === 0) {
8 console.log(`measurement with id {${measurement.id}} at time ${measurement.timestamp} has value [${measurement.value}]`);
9 }
10 }
11 });This is the result:
This is a very powerful mechanism. Instead of console.log() statements, imagine a line chart where the measurements gradually become visible as more data comes in.
This is an example created with Apache ECharts:
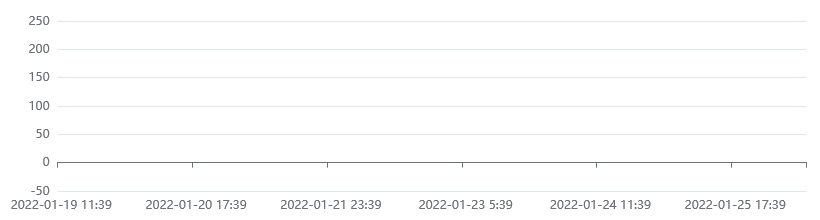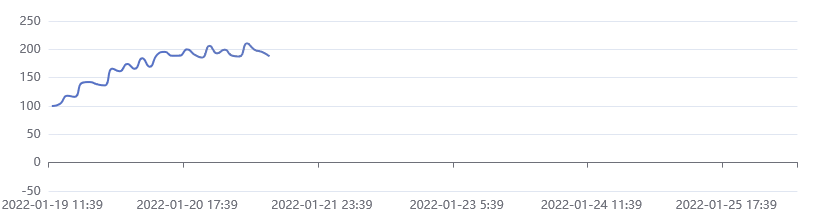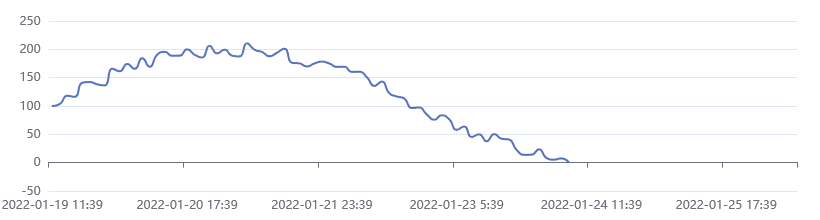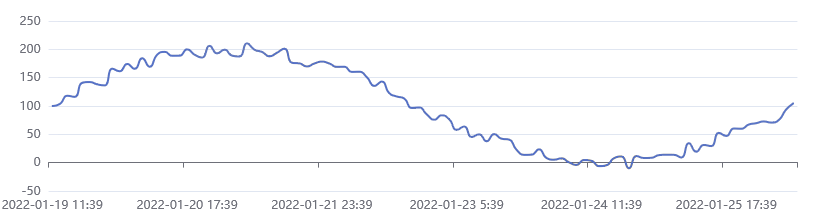
Before the Fetch API, it was impossible to do this because the alternative, XMLHttpRequest, will load the whole response into memory before providing it to your code.
Modern applications don't use XMLHttpRequest directly, but a lot of libraries like Axios or Angular's HttpClient rely on it to make requests.
People would rely on more advanced technologies like WebSockets to stream data.
HTTP/2 for Streaming
You might have heard that HTTP/2 has a more efficient mechanism for streaming, and you would be right. So let's see if we can use HTTP/2.
From the side of your webapp, the browser will automatically determine if it can communicate with the server over HTTP/2 and use it if it's available. The Fetch API will do this transparently, so you do not need to make any changes to your webapp.
What you need to do is make your API available over HTTP/2:
1const Koa = require('koa');
2const app = new Koa();
3app.use(async (ctx) => {
4if (ctx.request.url === '/measurements.json') {
5ctx.response.set('content-type', 'application/json');
6ctx.body = fs.createReadStream('./measurements.json');
7}
8});
9http2.createSecureServer(
10{
11key: fs.readFileSync(path.resolve('path/to/localhost-key.pem')),
12cert: fs.readFileSync(path.resolve('path/to/localhost.pem')),
13},
14app.callback(),
15).listen(3000);This code is mostly the same as for HTTP/1.1 with two notable differences:
- We're using Node's
http2module instead ofhttp. - We're using
HTTPSinstead of plainHTTPbecause this is mandatory for HTTP/2. You can set up HTTPS and get thecertandkeyfiles using mkcert. Or, use one of the other mechanisms described in this article: Use HTTPS for Local Development
That's it!
If you restart the API and check the network tab in Developer Tools, you'll see that your application will now stream over HTTP/2 (don't forget to update the URL in your webapp, start with https:// instead of http://).
HTTP Streaming Considerations
In the code above, we assumed that there was a function parseJsonStream(readableStream) that would parse a ReadableStream containing JSON into an async iterable of objects.
The difficulty is that reading from a ReadableStream will give you chunks of data that don't necessarily correspond to anything meaningful. To illustrate, let's take a look at this example:
1[
2 { "id": "1", "timestamp": "2022-01-19T10:39:00.000Z", "value": 239.34 },
3 { "id": "2", "timestamp": "2022-01-19T10:40:00.000Z", "value": 820.14 },
4 { "id": "3", "timestamp": "2022-01-19T10:41:00.000Z", "value": 926.03 },
5 { "id": "4", "timestamp": "2022-01-19T10:42:00.000Z", "value": 513.01 }
6]We could receive this JSON in chunks like this:
1[
2 { "id": "1", "timestamp": "2022-01-19T10:39:00.000Z", "value": 239.34 },
3 { "id": "2", "tim
4estamp": "2022-01-19T10:40:00.000Z", "value": 820.14 },
5{ "id": "3", "timestamp": "2022-01-19T10:41:00.000Z", "value": 926.03 },
6{ "id": "4", "timestamp": "2022-01-19T10:42
7:00.000Z", "value": 513.01 }
8]You need some way to determine where one measurement object starts and ends. To simplify this, we created a JSON file where each line contains precisely one object. Parsing the stream becomes manageable when we can make this assumption.
Here is the implementation of parseJsonStream(readableStream)
1async function *parseJsonStream(readableStream) {
2 for await (const line of readLines(readableStream.getReader())) {
3 const trimmedLine = line.trim().replace(/,$/, '');
4 if (trimmedLine !== '[' && trimmedLine !== ']') {
5 yield JSON.parse(trimmedLine);
6 }
7}
8
9}
10async function *readLines(reader) {
11const textDecoder = new TextDecoder();
12let partOfLine = '';
13for await (const chunk of readChunks(reader)) {
14const chunkText = textDecoder.decode(chunk);
15const chunkLines = chunkText.split('\n');
16if (chunkLines.length === 1) {
17partOfLine += chunkLines[0];
18} else if (chunkLines.length > 1) {
19yield partOfLine + chunkLines[0];
20for (let i=1; i < chunkLines.length - 1; i++) {
21yield chunkLines[i];
22}
23partOfLine = chunkLines[chunkLines.length - 1];
24}
25}
26}
27function readChunks(reader) {
28return {
29async* Symbol.asyncIterator {
30let readResult = await reader.read();
31while (!readResult.done) {
32yield readResult.value;
33readResult = await reader.read();
34}
35},
36};
37}If you have control over the API you're calling, you can use the "1 object per line" formatting as part of the contract, but know that it could be prone to breaking. For robust JSON support, we need a real streaming parser.
Other options include using a format with one object per line by default, like CSV, or a more advanced format with built-in support for streaming like Apache Arrow.
Advantages
- Snappy User Experience: You can start showing data as soon as it's available.
- Scalable API: No memory usage spikes from accumulating results in memory.
- Uses plain HTTP and a standard JavaScript API. There are no connections to manage or complicated frameworks that might become obsolete in a few years.
Disadvantages
-
Implementation is slightly more involved than using regular API calls.
-
Error handling becomes more difficult because HTTP status code 200 will be sent as soon as streaming starts. What do we do when something goes wrong in the middle of the stream?
When something goes wrong, your API should close the stream. Your webapp can then determine if the stream was complete and show a fitting message to the user if it's not. For example: when using a JSON response, as we discussed, you can check that the last line contains only "]".
-
No streaming JSON parser is currently available. Needs formatting assumptions as part of the contract or a more unconventional format.
Conclusion
You have learned how to stream HTTP data efficiently using Node.js and HTTP without congesting or burdening the memory. You have also understood the advantages and disadvantages of HTTP streaming.


