Introduction
OAuth didn’t suddenly become insecure; what changed is the way modern applications are built.
Today’s apps don’t live in a single, controlled backend anymore. They span browsers, mobile devices, APIs, third-party services, and client-side runtimes. Tokens move through redirects, deep links, JavaScript, SDKs, and proxies, often across systems you don’t fully control.
And along that journey, things can leak. Not because OAuth is broken, but because many of its original flows were designed for a simpler, server-centric world.
That shift is exactly why the OAuth PKCE (Proof Key for Code Exchange) flow has become the modern standard.
PKCE wasn’t introduced as an optional security upgrade it emerged as a necessary fix. Over time, teams ran into real-world issues: intercepted authorization codes, tokens exposed in browser environments, and mobile or SPA clients struggling to securely store secrets.
As frontend-heavy architectures became the norm, the traditional OAuth 2.0 Authorization Code Flow needed reinforcement and PKCE provided it.
What’s interesting is how quietly this shift happened. PKCE didn’t replace OAuth overnight. It started as a best practice for native apps, expanded to single-page applications (SPAs), and is now widely recommended across the OAuth ecosystem. Today, using Authorization Code with PKCE is no longer an edge-case decision it’s considered the secure default for public clients.
So when teams ask, “Do we really need PKCE?”, they’re asking the wrong question.
The real question is: What risks are you accepting if you don’t use PKCE in a world of browsers, mobile apps, and distributed systems?
This guide answers that clearly and practically. No protocol deep dives, no unnecessary complexity. Just a real-world explanation of how OAuth PKCE works, why it matters today, and when you should be using it by default.
Why OAuth Guidance Quietly Changed Over the Last Few Years
OAuth didn’t wake up one morning and decided to reinvent itself. The shift happened slowly, almost politely, while most teams were busy shipping features.
A decade ago, the typical OAuth client was a server-rendered web app. Secrets lived on the backend. Tokens rarely touched the browser. Redirects were predictable. Threat models were simpler because architectures were simpler.
That’s not the world we’re in anymore.
Today, frontends are applications. SPAs talk directly to APIs. Mobile apps act as first-class clients. Desktop apps, browser extensions, embedded webviews, everything wants to authenticate, and most of these environments can’t reliably protect secrets. Yet for years, we kept using flows that assumed they could.
That mismatch is what forced OAuth guidance to evolve.
The OAuth authorization code flow was always the safest option on paper, but it assumed a confidential client that could protect a client secret. As public clients became the norm, that assumption quietly collapsed.
The industry tried to patch around it lighter flows, fewer steps, more convenience but convenience came with a cost. Tokens showed up in places they didn’t belong. Authorization codes became easier to intercept than anyone wanted to admit.
PKCE was the course correction.
Originally introduced to protect native apps, PKCE addressed a very specific failure mode: what happens if the authorization code is stolen before it reaches the client that requested it? As browsers became more powerful and SPAs more common, that same problem started showing up everywhere, not just on mobile.
So guidance shifted. Not loudly. Not dramatically. Just consistently.
Newer recommendations stopped treating PKCE as “extra security” and started treating it as table stakes. Implicit flow quietly fell out of favor. Public clients were expected to prove continuity between the authorization request and the token exchange. The authorization code flow with PKCE stopped being the “advanced” option and became the sensible default.
If this feels like OAuth moved the goalposts, it didn’t. The field just caught up to how applications actually behave in production. PKCE didn’t change OAuth’s philosophy, it aligned it with reality.
And that’s why, when teams talk about modern OAuth today, they’re almost always talking about PKCE even when they don’t realize it yet.
PKCE in One Sentence
PKCE makes sure the app that starts an OAuth login is the only one that can finish it even if someone manages to grab the authorization code along the way. That’s it. That’s the core idea.
Everything else the hashes, parameters, and extra fields exists to answer one uncomfortable question OAuth had to face as apps moved into browsers and mobile runtimes: what if the authorization code leaks before it’s exchanged for tokens? In older setups, that question barely mattered. In modern apps, it matters all the time.
PKCE solves this by forcing continuity. When an app initiates login, it creates a secret value and proves later, during the token exchange, that it’s the same app coming back. If an attacker intercepts the code but doesn’t have that proof, the exchange fails. No token. No silent takeover.
This is why the proof key for code exchange isn’t just a clever name; it describes the exact role PKCE plays. It doesn’t encrypt OAuth. It doesn’t replace other protections. It simply removes the assumption that authorization codes will always travel safely through browsers, redirects, and mobile OS handoffs.
Once you see PKCE this way, the rest of the flow starts to make sense. And more importantly, it becomes obvious why modern OAuth guidance treats PKCE as the baseline rather than the exception.
How the OAuth PKCE Flow Actually Works
Here’s how it actually works without drowning in parameters or pretending this is a spec review.
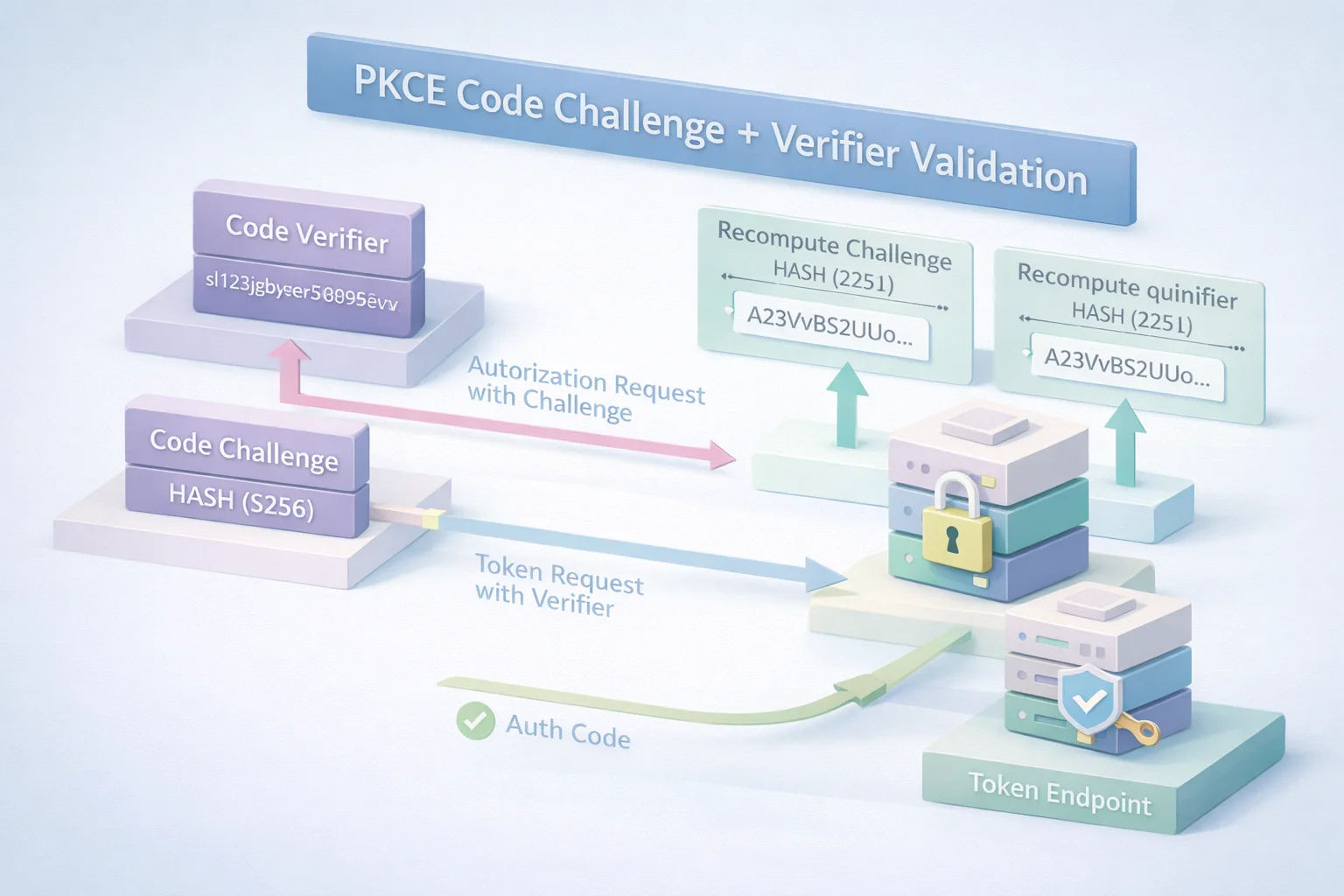
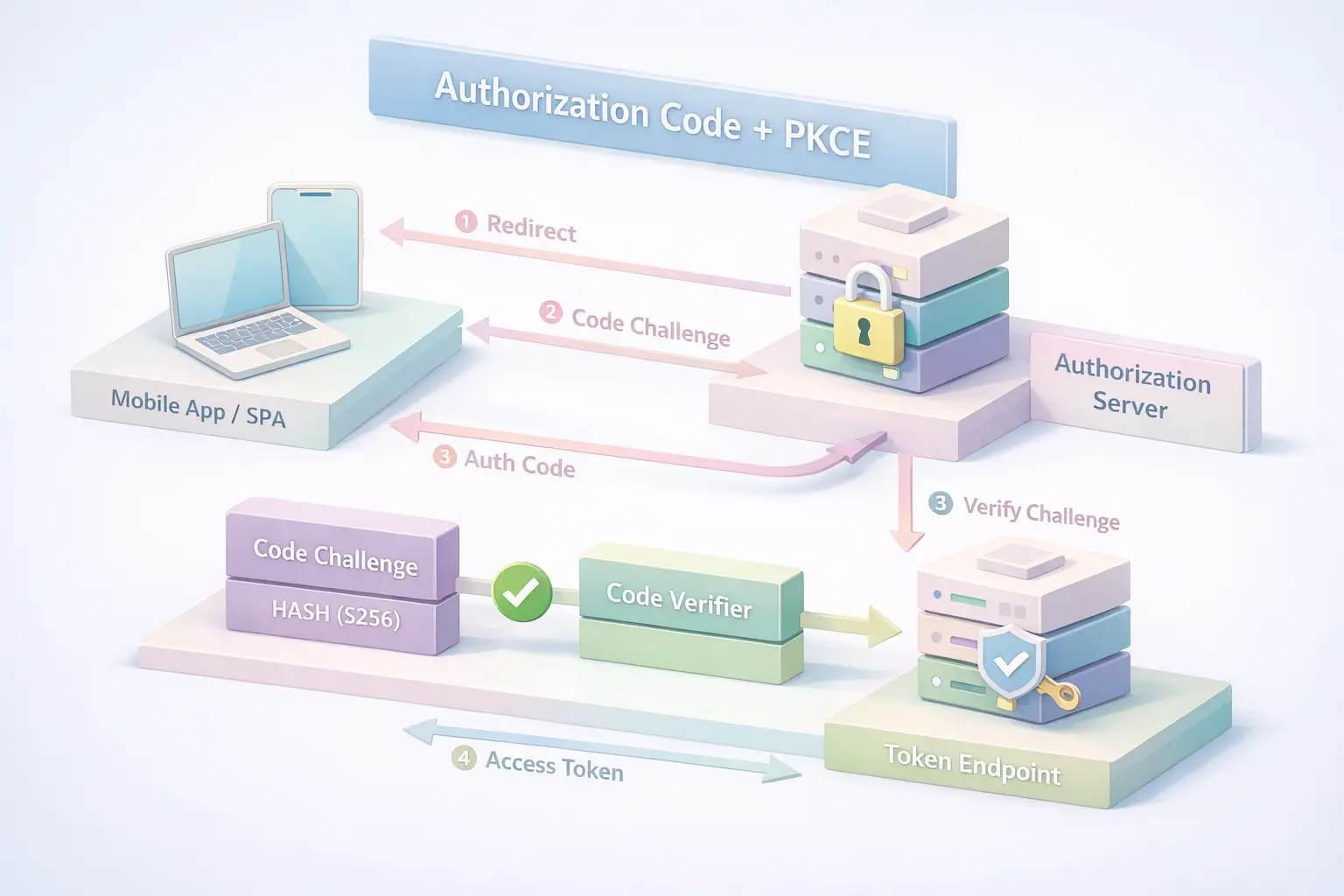
When an app starts a login using the OAuth PKCE flow, it does one important thing before redirecting the user to the authorization server: it generates a random, high-entropy value. This value never leaves the app. Think of it as a one-time secret tied to that specific login attempt.
From that value, the app derives what’s called a PKCE code challenge. This isn’t the secret itself it’s a transformed version, usually hashed, that’s safe to send along with the authorization request. At this point, nothing looks very different from a normal OAuth redirect, except for one extra parameter quietly riding along.
The user authenticates. Consent happens. An authorization code is issued. Now comes the part PKCE cares about.
When the app exchanges that authorization code for tokens, it sends the original secret the verifier along with the request. The authorization server takes that verifier, transforms it the same way it did earlier, and checks whether it matches the stored challenge. If it does, the exchange proceeds. If it doesn’t, everything stops right there.
This is where PKCE authentication changes the game. The authorization code by itself is no longer enough. Possessing the code doesn’t grant access unless you can also prove you’re the same client that initiated the flow. Intercepted codes lose their value. Replay attempts fall flat.
Nothing about this requires the app to store a long-lived secret. Nothing assumes the browser is trustworthy. And nothing relies on network paths behaving perfectly.
That’s why the authorization code flow with PKCE fits so well in modern architectures. It accepts the reality that frontends are exposed, mobile environments are noisy, and redirects are messy and it builds protection directly into the exchange itself.
Once you understand this flow, it becomes clear that PKCE isn’t an add-on. It’s the missing guardrail OAuth needed once public clients became the norm.
Why PKCE Changed the Risk Model for OAuth Clients
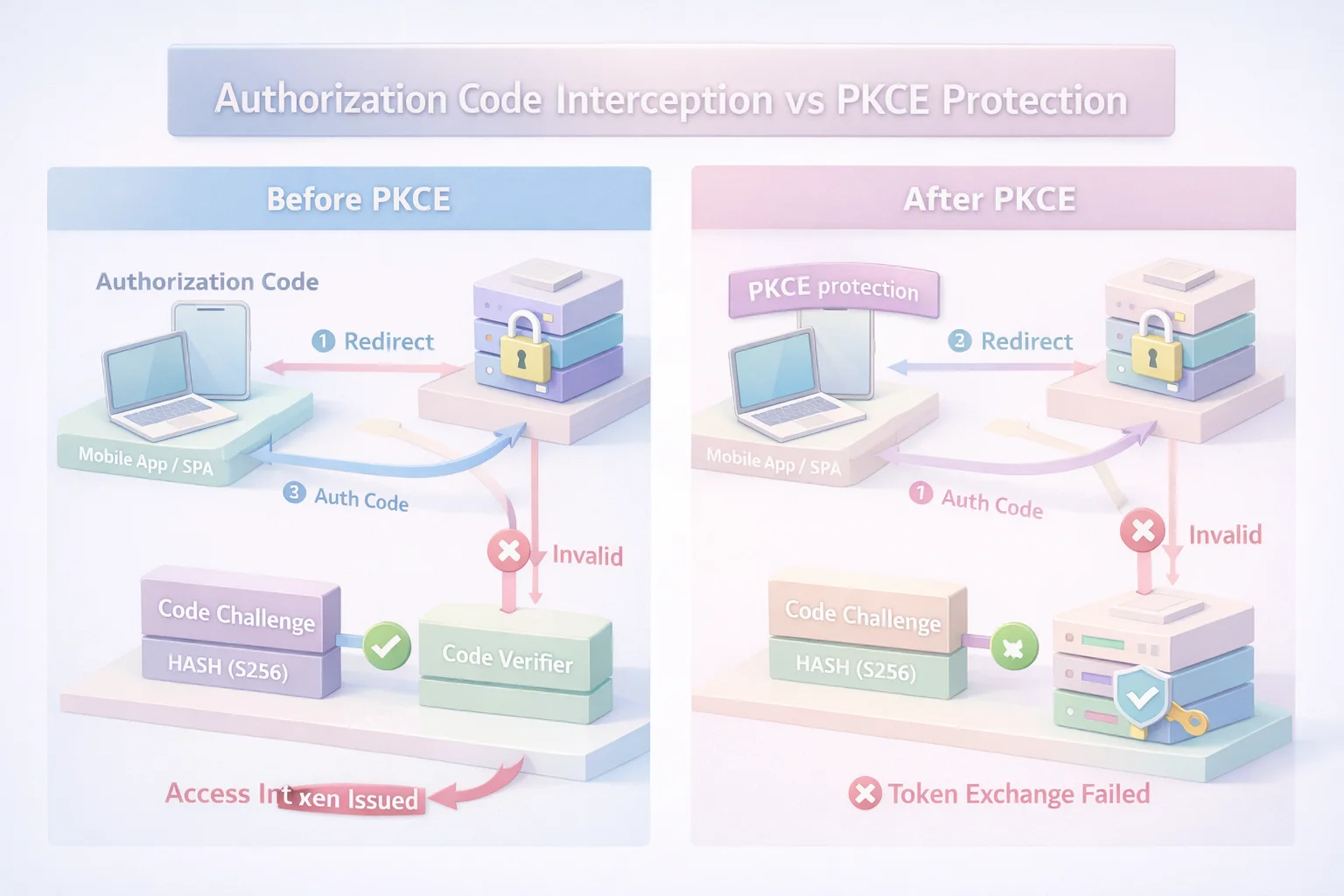
Before PKCE, OAuth trusted something it probably shouldn’t have: the journey between “authorization granted” and “token issued.”
That gap where an authorization code exists but hasn’t yet been exchanged used to feel harmless. Codes were short-lived. TLS was assumed. Clients were mostly servers. If a code leaked, the blast radius felt small. Modern apps broke that illusion.
Browsers expose more surface area than we like to admit. Redirects pass through history, logs, extensions, proxies, and OS-level handlers. Mobile apps bounce through deep links and custom schemes.
SPAs run in environments where any JavaScript running in the page can see what’s going on. The authorization code started spending more time in places attackers could realistically reach.
PKCE redraws that boundary.
With PKCE in place, the authorization code stops being a bearer artifact. It becomes half of a two-part check. On its own, it’s useless. The second half the verifier never travels through redirects or intermediaries. It stays inside the client that initiated the login.
This shifts the threat model in a very practical way:
-
Stealing a code is no longer enough
-
Replaying intercepted redirects stops working
-
Timing attacks against the code exchange lose their payoff
That’s why pkce authorization matters so much for public clients. It doesn’t assume the transport is perfect. It doesn’t assume the runtime is trusted. It simply assumes that something will leak and designs around that reality.
This is also why PKCE scales so cleanly across app types. Whether it’s a browser tab, a mobile app, or a desktop client, the same principle applies: prove continuity between the start and the end of the flow.
Once you see PKCE through this lens, it’s easier to understand why newer OAuth guidance treats it as a baseline control. Not because the protocol got stricter but because the environments around it got messier.
Where Teams Usually Go Wrong With PKCE
Most PKCE failures don’t come from misunderstanding the spec. They come from underestimating why PKCE exists in the first place.
The most common mistake? Treating PKCE like optional hardening. Something you add later. Something you toggle on only for mobile. In reality, PKCE is doing foundational work protecting the weakest, most exposed part of the OAuth authorization code flow. Skipping it doesn’t make your app “slightly less secure.” It reintroduces the exact risk PKCE was designed to eliminate.
Another pattern shows up in implementations that technically “support” PKCE but cut corners. Using weak challenge methods. Falling back to non-hashed values because a library made it easier. At that point, the pkce code challenge exists in name only. The protection becomes theoretical, not practical.
Redirect handling is where things quietly unravel. Teams lock down PKCE correctly, then loosen redirect URI matching to support multiple environments or quick demos. Wildcards creep in. Partial matches sneak through. The result? You’ve protected the code exchange while leaving the door open earlier in the flow.
There’s also a persistent misconception that PKCE replaces everything else. It doesn’t. PKCE authentication doesn’t remove the need for proper state validation, careful token storage, or disciplined frontend security practices. It solves one specific problem extremely well and assumes you won’t sabotage it elsewhere.
The subtle mistake, though, is mindset. Teams often approach PKCE as a feature to “implement” rather than a baseline assumption for public clients. Once you think of it as optional, it becomes negotiable. Once it becomes negotiable, it’s usually the first thing dropped when timelines tighten.
PKCE works best when it’s boring. Invisible. Non-negotiable. That’s when the oauth authorization code flow behaves the way modern apps expect it to.
Which Applications Should Be Using Authorization Code Flow with PKCE
If your app ever shows a login screen in a browser or something pretending to be one PKCE should already be part of the design.
Single-page applications are the obvious case. They run entirely in the browser, talk directly to APIs, and can’t keep a client secret even if they try. For these apps, the authorization code flow with PKCE isn’t a security upgrade it’s the minimum bar. Anything else assumes a level of control the browser simply doesn’t give you.
Mobile apps fall into the same category, even though they feel more contained. Deep links, custom URI schemes, OS handoffs, and shared device state all create opportunities for codes to leak. That’s exactly why PKCE showed up there first. In mobile environments, pkce authentication isn’t defensive it’s realistic.
Server-rendered web apps are where teams hesitate. “We have a backend,” the argument goes. “We can keep secrets.” And technically, yes you can. But once a browser is involved, once redirects and front-channel flows enter the picture, PKCE still closes a gap you don’t want open.
That’s why more teams quietly include PKCE here too. It costs almost nothing, and it removes an entire class of edge-case risk.
Even hybrid setups SPAs backed by APIs, mobile apps sharing identity infrastructure with web properties benefit from standardizing on the oauth pkce flow. Fewer special cases. Fewer “this app is different” exceptions. Fewer security decisions that depend on architectural memory instead of enforcement.
The pattern is simple: If your client is public, semi-public, or exposed to a browser-like environment, PKCE belongs in the flow. The list of apps that don’t fit that description is much shorter than it used to be.
When PKCE Is Not the Right Tool
PKCE is powerful but it’s not universal, and treating it that way creates its own kind of mess.
The clearest case where PKCE doesn’t belong is machine-to-machine communication. When there’s no human, no browser, and no front-channel redirect, the risks PKCE is designed to reduce simply don’t exist.
Service accounts, background jobs, and backend integrations authenticate in controlled environments where secrets can be protected. Adding PKCE there doesn’t increase security it just adds confusion.
The same applies to fully confidential server-side flows that never expose authorization codes to the browser at all. If the entire OAuth exchange happens backend-to-backend, the threat model is already constrained. PKCE doesn’t hurt in these cases, but it doesn’t meaningfully change the risk either.
Another place teams stumble is trying to force PKCE into legacy systems without understanding the surrounding flow. Older identity setups built around implicit assumptions, long-lived sessions, non-standard redirects, embedded webviews often struggle when PKCE is bolted on without cleaning up the rest of the pipeline.
That friction isn’t PKCE’s fault, but it’s a signal that the surrounding architecture needs attention.
The key distinction is intent. PKCE authorization exists to protect public clients operating in exposed environments. When those conditions aren’t present, PKCE loses its purpose. It’s not a general authentication mechanism. It’s a targeted safeguard.
Knowing where not to use PKCE is just as important as knowing where to use it. Otherwise, teams end up blaming the tool for problems that actually come from mismatched assumptions.
Implementation Rules That Hold Up in Production
This is the part most guides rush through and the part that decides whether PKCE actually protects you or just looks good in a diagram.
Start with the basics and don’t compromise on them. The verifier must be truly random and high-entropy. Not a UUID. Not something derived from the user state. Generate it using a cryptographically secure random function every single time. If that verifier is predictable, the rest of the flow collapses quietly.
When generating the PKCE code challenge, stick to hashed methods. Plain challenges exist mostly for backward compatibility, not because they’re a good idea. In real systems, hashed challenges dramatically reduce the value of anything that leaks mid-flow. If a library defaults to something weaker, override it. Convenience defaults are a common source of subtle risk.
Redirect URIs deserve more discipline than they usually get. Exact matching isn’t pedantry, it’s containment. Wildcards and partial matches are how authorization responses end up where they shouldn’t. PKCE protects the code exchange, but it doesn’t fix sloppy redirect handling earlier in the flow.
State validation still matters. PKCE does not replace CSRF protection. Treat state as mandatory, not optional, and validate it strictly. If you’re layering OpenID Connect on top, nonce handling deserves the same attention. PKCE narrows the attack surface; it doesn’t eliminate the need for basic hygiene.
Token handling is where many otherwise-solid implementations stumble. PKCE ensures you receive tokens safely but what you do next is on you. Storing tokens in insecure browser locations, overexposing them to frontend code, or skipping rotation strategies undoes much of the benefit PKCE provides.
The real rule here is mindset. Implement PKCE as infrastructure, not as a feature. Once it’s part of the default flow, these decisions stop feeling like trade-offs and start feeling like guardrails.
With these rules in place, the authorization code flow with PKCE stops being fragile. It becomes boring and boring is exactly what you want in authentication.
Why Auth Code + PKCE Is No Longer “Advanced OAuth”
There was a time when adding PKCE felt like extra work. More parameters. More moving parts. Another thing to explain to the team.
That time has passed.
What changed isn’t the complexity of PKCE, it’s the baseline risk of modern applications. Browsers are no longer thin clients. Mobile apps aren’t isolated containers. Frontends initiate sensitive flows, handle redirects, and interact directly with identity systems. In that world, assuming the authorization code will always travel safely is no longer a reasonable default.
This is why the OAuth PKCE flow quietly replaced older patterns instead of competing with them. It didn’t add new concepts to OAuth; it corrected an assumption that no longer holds. The assumption that the client receiving the authorization code is always the one exchanging it.
Once you remove that assumption, PKCE stops looking like an enhancement and starts looking like a missing piece.
This shift is also why the industry stopped framing PKCE as “for mobile only” or “for high-risk apps.” Public clients are everywhere now. Even applications that feel backend-heavy still rely on front-channel redirects and browser contexts. The line between confidential and public clients blurred, and OAuth adapted accordingly.
Teams that still view PKCE as advanced often end up with fragmented identity setups, different flows for different apps, exceptions layered on top of exceptions. Teams that standardize on authorization code flow with PKCE usually see the opposite: fewer edge cases, fewer security debates, and a cleaner mental model across platforms.
Auth Code + PKCE isn’t special anymore. It’s boring by design. And in authentication, boring is a sign that the system is finally aligned with reality.
Conclusion: If Your App Has a Browser, PKCE Should Already Be There
At this point, the pattern is hard to ignore.
If an application relies on a browser, a mobile runtime, or any public client that initiates OAuth on behalf of a user, PKCE is no longer a design choice, it's an expectation. The environments we deploy into are noisy, exposed, and imperfect, and pretending otherwise is how small gaps turn into serious incidents.
The OAuth PKCE flow didn’t become dominant because it’s elegant or new. It became dominant because it survives real conditions: intercepted redirects, shared devices, unpredictable client behavior, and frontends that do more than they were ever meant to. It accepts that things leak and removes the value of what leaks most often.
This is why Authorization Code with PKCE has quietly become the default posture across modern OAuth guidance. Not because older flows stopped working, but because they rely on assumptions modern apps no longer meet. PKCE closes that gap without asking clients to keep secrets they can’t protect.
If your team is still debating whether PKCE is “necessary,” that debate is already behind the curve. The more useful question now is whether your current implementation fully commits to it or quietly weakens it through shortcuts and exceptions.
Choose PKCE by default. Make it boring. Make it non-negotiable. That’s how OAuth stops being fragile and starts behaving like infrastructure again.
Ready to Stop Treating OAuth as a Guessing Game?
If your authentication flow still depends on assumptions that don’t hold anymore, it’s time to fix that, not patch it.
Adopt the OAuth PKCE flow as your default. Remove the edge cases. Eliminate silent risks. Build an identity layer that behaves predictably, even under real-world conditions.
And if you’d rather not wire all of this from scratch. LoginRadius gives you production-ready Authorization Code + PKCE, secure token handling, and flexible integrations out of the box.
Start building with a PKCE-first authentication flow today
Or talk to our team to see how it fits your architecture
Because authentication shouldn’t be something you keep revisiting. It should just work.
FAQs
Q: Is PKCE required for OAuth today?
A: For public clients like SPAs and mobile apps, PKCE is effectively the default. Modern OAuth guidance assumes authorization code flow is used with PKCE, not without it.
Q: Does PKCE replace the client secret?
A: No. PKCE doesn’t replace client secrets—it solves a different problem. It protects the authorization code exchange when a client can’t safely store a secret.
Q: Can backend web apps skip PKCE?
A: They technically can, but many teams still use PKCE because browsers and redirects are involved. It removes edge-case risk with almost no downside.
Q: Is PKCE enough to secure OAuth by itself?
A: PKCE protects the code exchange, not the entire flow. You still need proper state validation, strict redirect URIs, and safe token handling.



