Introduction
Here’s the uncomfortable truth: most login systems aren’t being “hacked.” Credential stuffing attacks don’t guess passwords. They replay them. Attackers take billions of username and password combinations from previous data breaches and systematically test them against your login endpoint. If users reuse passwords which many of them still do, then the bots have simply walked into your systems.
That’s what makes credential stuffing attacks so dangerous. There’s no malware. No SQL injection. No loud alarms. Just valid credentials being tried at machine speed across thousands of accounts. From your application’s perspective, it looks like a normal login attempt. From the attacker’s perspective, it’s automation at scale.
So, what is credential stuffing in simple terms? It’s an automated attack where bots use stolen credentials from one breach to gain access to accounts on another platform. And because password reuse is common, it works far more often than companies would like to admit.
In 2026, these attacks are not rare spikes. They are a constant background noise. Every public login endpoint is scanned, tested, and replayed against on a daily basis. Bots now outnumber humans on many authentication surfaces, especially in fintech, ecommerce, gaming, and SaaS platforms.
Modern bots rotate IP addresses using residential proxy networks. They mimic browser behavior. They randomize timing. Basic rate limits barely slow them down. CAPTCHA alone is no longer a serious credential stuffing defense.
If your only strategy to prevent credential stuffing is “lock the account after five failed attempts,” you’re not stopping attackers. You’re rate-limiting real users while bots quietly distribute attempts across thousands of IPs.
Credential stuffing mitigation today requires layered intelligence rate limits tied to behavior, device signals that expose automation, and IP intelligence that understands threat patterns in real time. Not one control, one rule. But a well co-ordinated defense model.
The question is no longer how to prevent credential stuffing attack attempts entirely, you won’t. The real question is how quickly you can detect credential stuffing, assess risk, and stop account takeover before it becomes a breach headline. If your login is public, it is already being tested by hackers. Let’s talk about how to defend it properly.
What Is Credential Stuffing? (And Why It Works So Well)
Credential stuffing is an automated attack where bots use stolen username and password combinations from previous data breaches to attempt login on other websites. It relies on one simple assumption: people reuse passwords.
That assumption is usually correct. When a retail site, social platform, or SaaS tool gets breached, attackers collect credential dumps, often called “combo lists.” These lists are then fed into automated bot frameworks that attempt authentication across banking apps, ecommerce sites, fintech platforms, streaming services, and enterprise tools.
No guessing is required. The passwords are real. They already worked somewhere else.
This is what separates credential stuffing attacks from traditional brute force attacks. Brute force tries many random password combinations against one account. Credential stuffing tries one known combination across many accounts and many platforms. It’s quieter, more efficient, and more scalable.
There’s also password spraying, where attackers try one common password across many accounts. But credential stuffing is more precise. It uses verified breach data, which dramatically increases success rates.
Why does credential stuffing work so well?
#1: Password reuse remains common despite years of security awareness campaigns. Users prioritize convenience over uniqueness. One leaked password becomes a master key to multiple accounts.
#2: Automation frameworks have matured. Attackers configure automated bot frameworks using specialized account checker software. These platforms allow hackers to upload custom configuration plugins, modify request headers, rotate proxies, randomize user agents, and simulate browser-like behavior. These bots are no longer crude scripts. They are engineered systems attacking at machine speed.
#3: Attacks are distributed. Instead of hammering one account from one IP address, modern bots spread login attempts across thousands of IPs using residential proxy networks. This makes detection harder, and simple IP-based blocking is ineffective.
From a system perspective, each request looks like a normal login attempt. Valid username. Valid password format. Clean HTTP request. No obvious anomalies. That’s why credential stuffing protection cannot rely on single-signal detection. You’re not blocking malformed traffic. You’re distinguishing automated credential replay from legitimate user authentication.
| Attack Type | Dataset/Method Used | Targeting Strategy | Detection Difficulty |
|---|---|---|---|
| Brute Force | Generates random alphanumeric combinations. | Many attempts against one single account. | Easy (Triggers basic per-IP or per-account rate limits). |
| Password Spraying | Tests a single common password (e.g., Password123). | Spreads across many accounts globally. | Medium (Stays below single-account lockouts). |
| Credential Stuffing | Replays verified username/password "combo lists" from past breaches. | Tested systematically across millions of accounts and platforms. | High (Blends into normal authentication traffic using rotated IPs). |
If you're new to credential stuffing attacks, read our foundational guide here.
Understanding this difference is the foundation of effective credential stuffing defense. If you treat it like brute force, you’ll defend it like brute force, and you’ll lose quietly.
The Cost of Account Takeover (ATO)
Credential stuffing is the leading vector for ATO. Beyond brand damage, successful replay attacks trigger regulatory scrutiny under GDPR and CCPA due to credential exposure. Securing the login endpoint is no longer a purely operational concern it is an explicit regulatory audit item for modern enterprise platforms.
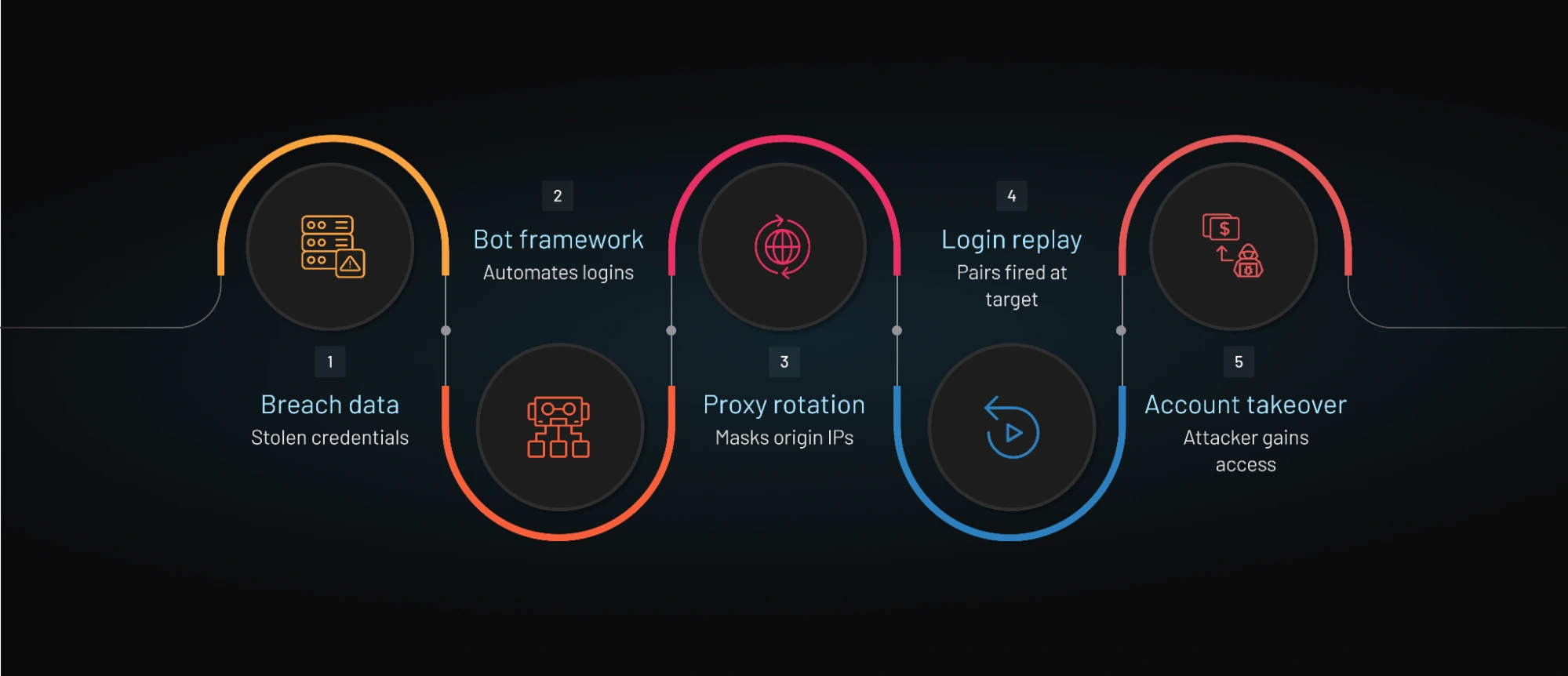
Anatomy of a Modern Credential Stuffing Attack
Credential stuffing attacks are structured, automated workflows. They are not chaotic bursts of traffic. They follow a predictable sequence designed for efficiency and stealth.
-
Breach data acquisition. Attackers collect username and password pairs from past data leaks. These datasets are widely available in underground forums and are often aggregated into massive “combo lists” containing millions or billions of credentials.
-
Automation setup. Attackers configure bot frameworks that can send high volumes of login requests to a target application. These frameworks allow customization of headers, request timing, user agents, and proxy routing to resemble legitimate browser traffic.
-
Proxy rotation. Instead of sending requests from a single IP address, the bot distributes login attempts across thousands of IPs, often through residential proxy networks. This avoids triggering simple IP-based rate limits and spreads traffic in a way that looks geographically diverse.
-
Login replay. The bots systematically test credential pairs against the login endpoint. Each attempt may look completely normal, a valid username and password submitted through a standard authentication request.
-
Account exploitation. When valid credentials are found, the attacker gains access to the account. At this stage, the goal shifts from access to exploitation. This may involve extracting stored payment data, changing account details, draining reward balances, or reselling verified accounts in secondary markets.
What makes these attacks difficult to detect is not volume alone. Its distribution and realism. Each individual login attempt may not appear suspicious. The attack signal only becomes clear when you analyze patterns across sessions, devices, IP ranges, and velocity metrics.
Traditional systems often fail here. If monitoring is limited to per-IP thresholds or simple failure counts, distributed attacks remain below detection limits. Bots adapt. They slow down. They randomize intervals. They simulate human-like behavior.
This is why understanding how to detect credential stuffing requires looking beyond isolated events. The real signal emerges from correlated behavior across users, devices, and networks.
Credential stuffing attack prevention begins with recognizing that login abuse today is engineered to blend in. It does not announce itself loudly. It hides inside what appears to be normal authentication traffic.
Why Rate Limiting Alone Is Not Credential Stuffing Defense
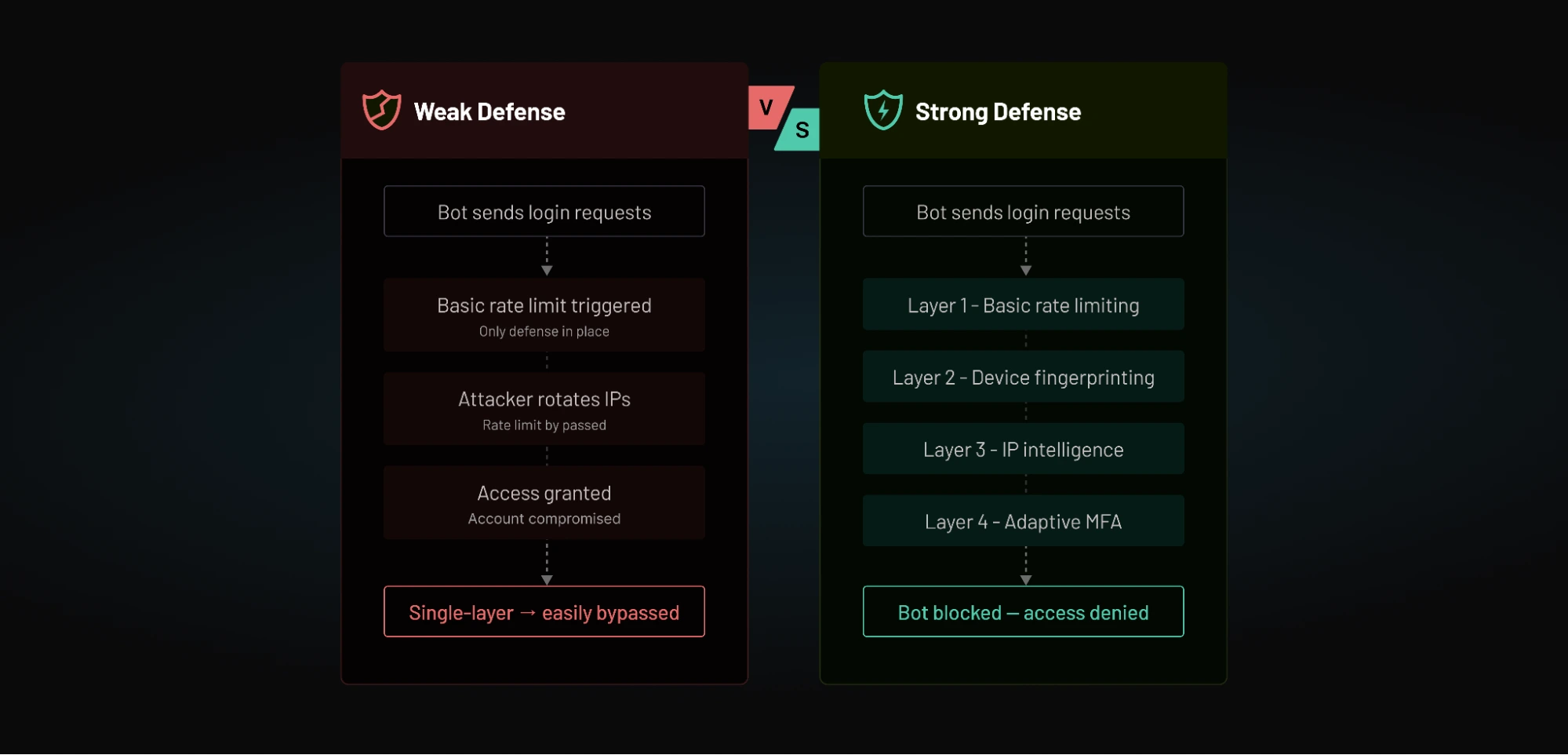
Rate limiting is usually the first control teams deploy to prevent credential stuffing. It sounds logical. If too many login attempts happen too quickly, slow them down or block them. The problem is that modern credential stuffing attacks are designed specifically to bypass basic rate limits.
When distributed bots hit your login endpoints simultaneously, the threat isn't just limited to compromised user accounts. The massive volume of automated requests can lead to severe system latency or recorded application downtime, transforming a quiet account-takeover attempt into an availability crisis.
Traditional rate limiting works at the IP level. If one IP sends too many requests in a short time window, it gets throttled or blocked. That model assumes attackers will send traffic from a small number of identifiable sources. They don’t.
Today’s bots distribute login attempts across thousands of IP addresses using proxy pools. Residential proxies make traffic look like it originates from real home users. Each IP sends only a small number of requests, staying under typical thresholds. The overall attack volume is high, but no single IP appears aggressive.
Per-account rate limits also have limitations. Credential stuffing doesn’t focus on one account. It spreads attempts across thousands of accounts using different username-password pairs. Each account may only receive one or two login attempts, which looks harmless in isolation.
So yes, rate limiting is necessary. But it is not a credential stuffing defense on its own. It is a speed bump, not a barrier.
Effective credential stuffing mitigation requires intelligent rate control. That means analyzing velocity patterns across multiple dimensions: IP, device fingerprint, ASN, geolocation, and session behavior. It means recognizing abnormal distributed activity rather than just high-frequency activity.
For example, if hundreds of login attempts originate from different IPs but share similar device signals or browser entropy patterns, that correlation is meaningful. If login attempts spike from newly observed IP ranges within a short window, that is meaningful. Basic rate limiting will not catch this.
To truly prevent credential stuffing, rate limits must be adaptive. Low-risk traffic flows normally. Medium-risk traffic may be slowed or challenged. High-risk traffic triggers step-up authentication or blocking.
Rate limiting is one layer of credential stuffing protection. It cannot carry the entire defense model. If your strategy stops at “five failed attempts per IP,” you are defending against yesterday’s attack pattern.
Device Signals: The Silent Bot Detector
If IP addresses can rotate, and passwords can be valid, what’s left to analyze?
The device. Device signals are one of the strongest layers in modern credential stuffing defense because bots struggle to convincingly mimic real device identity at scale.
A real user logs in from a consistent environment, browser version, operating system, screen resolution, rendering engine behavior, installed fonts, time zone, and hardware characteristics. These attributes combine to create a behavioral and technical fingerprint.
Bots, even sophisticated ones, often run in headless browsers or automation frameworks. They may randomize user agents, but deeper signals such as WebGL behavior, canvas rendering output, browser entropy, and execution timing patterns reveal inconsistencies.
This is where credential stuffing mitigation becomes more precise. Instead of asking, “How many attempts came from this IP?” the system asks, “How many attempts share similar device characteristics across distributed IPs?”
For example, hundreds of login attempts might originate from different residential IPs but share near-identical browser entropy patterns. That correlation indicates automation, not coincidence.
Device signals also enable reputation scoring. If a specific device fingerprint has attempted logins across thousands of accounts in a short period, it can be classified as high risk regardless of IP rotation.
Another detection layer involves behavioral consistency. Humans hesitate. They type. They occasionally mistype. Bots submit credentials with uniform timing and structured patterns. Even small timing anomalies can signal automation.
This approach answers the question of how to detect credential stuffing more effectively than static thresholds. Instead of reacting to volume alone, you analyze intent and pattern.
Credential stuffing protection improves significantly when device intelligence is layered with rate control. An IP may look clean. A password may be valid. But if the device fingerprint exhibits automation traits, the login attempt becomes high risk.
Bots can rotate IPs easily. Rotating a believable device identity at scale is much harder.
That’s why device signals have become a critical pillar in preventing credential stuffing in modern authentication systems.
IP Intelligence: The Layer Everyone Underestimates
IP addresses alone are not reliable indicators anymore. But ignoring them entirely is equally risky. The difference lies in how you interpret them.
IP intelligence goes beyond counting requests. It evaluates the quality, history, and context of the IP making the login attempt.
Modern credential stuffing attacks frequently rely on residential proxy networks. These IPs appear legitimate because they originate from real consumer internet providers. Blocking them outright would impact real users. That’s why simplistic blacklists fail.
Instead, IP intelligence looks at patterns such as ASN ownership, hosting provider classification, proxy detection signals, and historical threat data. If an IP range has been associated with bot traffic or login abuse across multiple platforms, that reputation score matters.
Geolocation anomalies are another strong signal. If an account consistently logs in from one region and suddenly receives multiple attempts from geographically diverse locations within minutes, that deviation is meaningful. Even when each IP appears clean individually, the collective pattern suggests credential replay.
Impossible travel detection strengthens this layer. If a user logs in from Mumbai and two minutes later another attempt appears from Eastern Europe, the system should flag it. Not because the IP is inherently malicious, but because the behavior defies physical plausibility.
IP velocity across distributed networks also reveals intent. Hundreds of login attempts originating from newly observed IP ranges within a short timeframe indicate coordinated activity. This is especially important for credential stuffing attack prevention in high-volume environments.
IP intelligence becomes powerful when combined with device and behavioral signals. A medium-risk IP combined with a high-risk device fingerprint significantly raises overall threat confidence. A low-risk IP paired with normal user behavior lowers it.
This layered evaluation helps prevent credential stuffing without aggressively blocking legitimate users. It reduces false positives while maintaining strong protection.
Credential stuffing defense is not about distrusting every IP. It is about understanding IP context in real time and correlating it with broader risk indicators.
When IP intelligence operates as part of a unified risk model, login abuse becomes visible before account takeover happens.
The Layered Credential Stuffing Defense Model
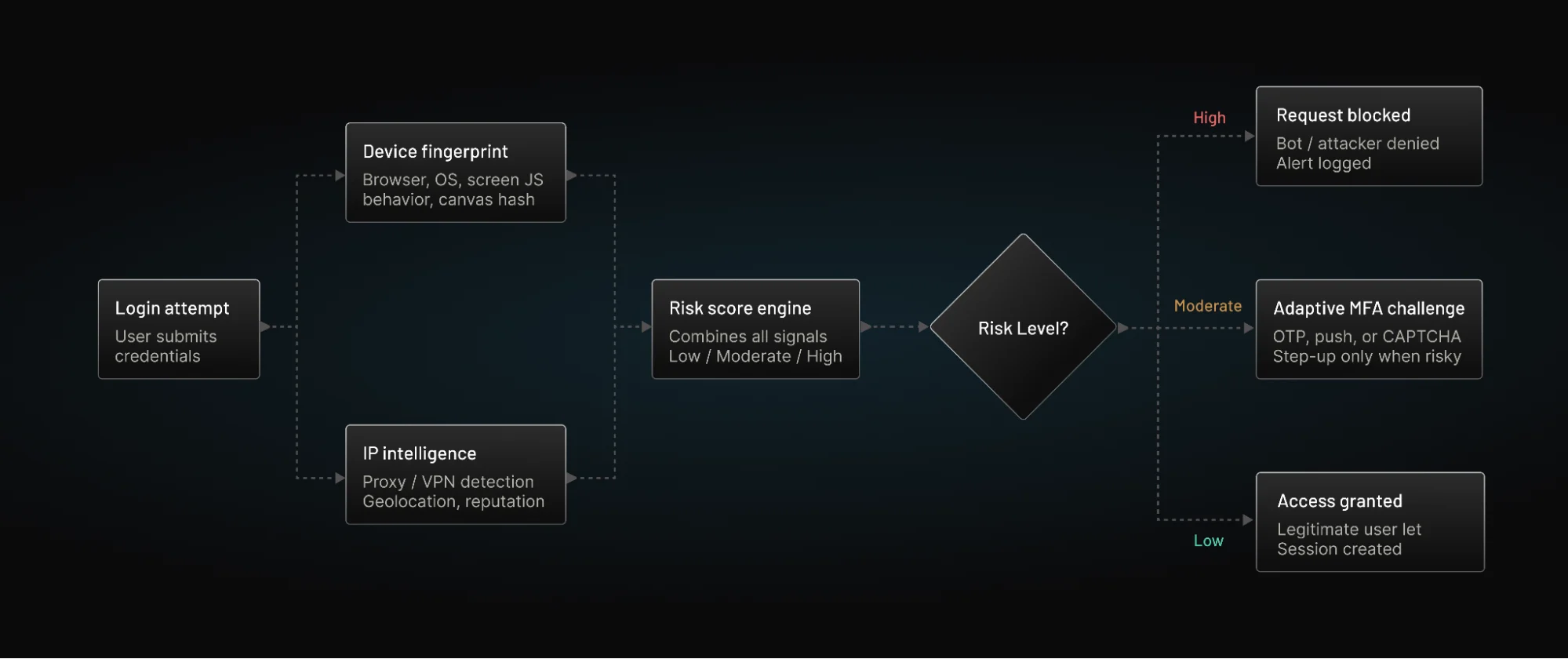
No single control stops credential stuffing attacks. Not rate limits. Not CAPTCHA. Not IP blocking. Modern defense works only when multiple signals operate together.
The first layer is intelligent rate control. Instead of static per-IP thresholds, the system evaluates distributed velocity across IPs, devices, and accounts. Sudden spikes in login attempts across wide account ranges signal automated credential replay, even if each individual request appears normal.
The second layer is device intelligence. Device fingerprints, browser entropy, execution timing patterns, and automation detection signals expose bots attempting to simulate legitimate sessions. Even when IPs rotate, device traits often reveal consistency across attempts.
The third layer is IP and network reputation. ASN classification, proxy detection, historical abuse data, and geolocation anomalies help identify coordinated login activity. This layer adds environmental context to the login request.
The fourth layer is adaptive response. Instead of blocking everything, the system assigns risk scores. Low-risk logins proceed normally. Medium-risk attempts may trigger step-up authentication such as MFA or email verification. High-risk attempts are throttled or blocked entirely. This balance is critical for preventing credential stuffing without degrading user experience.
The fifth layer extends beyond login. Account takeover monitoring tracks unusual post-authentication behavior, such as rapid profile changes, password resets, or payout modifications. Even if a credential stuffing attempt succeeds, damage can still be contained.
This layered model transforms credential stuffing mitigation from reactive blocking to real-time risk orchestration. It reduces dependency on any single signal and lowers false positives while increasing detection confidence.
Credential stuffing protection becomes effective when decisions are based on correlated signals rather than isolated events. Rate limits detect abnormal speed. Device signals expose automation. IP intelligence provides environmental context. Adaptive authentication applies proportional friction.
Preventing credential stuffing at scale requires accepting that login abuse is continuous. Defense must be continuous as well dynamic, correlated, and risk-aware. Anything less is just filtering noise while bots adapt around it.
How to Detect Credential Stuffing in Production
Detection is where most credential stuffing defense strategies either succeed or quietly fail. If you cannot see the attack clearly, you cannot respond effectively.
The first signal to monitor is login failure ratio. A sudden increase in failed authentication attempts across many accounts often indicates credential replay. However, raw failure count alone is not enough. The pattern of distribution matters more than the total number.
Distributed login attempts across many IP addresses targeting many different accounts within a short timeframe is a strong indicator. Legitimate traffic rarely behaves this way. Real users do not attempt one login per account across thousands of profiles in rapid succession.
Device entropy similarity is another critical detection signal. When multiple login attempts originate from different IP addresses but share highly similar device fingerprints, browser characteristics, or automation signatures, it suggests coordinated bot activity rather than unrelated human users.
Velocity patterns also reveal intent. Uniform request intervals, identical session flows, or consistent submission timing indicate scripted behavior. Humans introduce variability. Bots introduce precision.
Geolocation dispersion adds another detection dimension. If login attempts for multiple unrelated accounts originate from widely distributed regions within minutes, especially from newly observed IP ranges, this suggests proxy-based credential stuffing rather than organic growth.
To effectively detect credential stuffing, telemetry must be centralized. Login events, device fingerprints, IP metadata, risk scores, and authentication outcomes need to be analyzed together. Isolated logs will not expose distributed patterns.
Automated risk engines can evaluate these correlated signals in real time. Security operations teams can then focus on high-confidence threats instead of chasing false positives triggered by simple rate thresholds.
Preventing credential stuffing begins with reliable detection. Detection begins with visibility across behavior, device identity, and network context.
If you only monitor login failures, you are seeing fragments of the picture. If you correlate patterns across signals, the attack becomes visible before accounts are compromised.
Preventing Credential Stuffing: Practical Implementation Guide
Detection without response does not prevent credential stuffing. Once you can see the attack, the next step is structured mitigation.
Start by instrumenting your login endpoint properly. Capture IP metadata, ASN details, device fingerprint signals, request timing, success and failure states, and geolocation context. Without structured telemetry, advanced credential stuffing mitigation is impossible.
Next, introduce real-time risk scoring. Every login attempt should be evaluated across multiple dimensions: velocity, device reputation, IP reputation, and behavioral consistency. The goal is not to block immediately, but to classify risk accurately.
Then implement adaptive controls. Low-risk logins should proceed without friction. Medium-risk attempts can trigger step-up authentication such as MFA, email verification, or WebAuthn challenge. High-risk attempts should be throttled or blocked outright. This approach prevents credential stuffing attack escalation while protecting legitimate users.
Rate controls should be dynamic, not static. Instead of fixed thresholds, apply contextual limits based on account sensitivity, historical behavior, and traffic baselines. An ecommerce site during a flash sale behaves differently from a banking login at midnight. Risk models must reflect this.
Introduce device-based reputation tracking. If a specific fingerprint attempts to log in across hundreds of accounts, future attempts from that device should automatically carry a higher risk weight. This prevents repeated credential replay campaigns from reusing infrastructure.
Layer IP intelligence feeds into the decision engine. Known proxy networks, flagged ASNs, and recently observed malicious ranges should elevate risk scores. However, avoid blunt blocking that impacts real users on shared networks.
Finally, monitor post-login behavior. Preventing credential stuffing does not end at authentication. Rapid password changes, payout modifications, or unusual data access after login may signal account takeover following successful credential replay.
Effective credential stuffing protection is iterative. Signals improve over time. Risk models refine with data. Controls adjust based on evolving attack patterns.
Preventing credential stuffing is not about eliminating attempts entirely. It is about ensuring automated credential replay cannot scale into account takeover.
That requires visibility, correlation, and proportional response not just another CAPTCHA added at the login form.
The Login Endpoint Telemetry Checklist
Before deploying advanced risk scoring, ensure your application payload records the following variables at the /login controller:
[ ] Network Layer: Client IP, ASN (Autonomous System Number) classification, and True-Client-IP headers (via CDN/WAF proxy).
[ ] Client Environment: User-Agent string, HTTP request header ordering, and Javascript-derived canvas/WebGL device fingerprints.
[ ] Behavioral Metrics: Keystroke dynamics (typing speed), time-to-submit login button click, and session creation-to-auth attempt velocity.
Why Passwords Alone Cannot Be Secured
Credential stuffing attacks succeed because passwords are portable. Once exposed in one breach, they can be reused anywhere the user has repeated them.
No amount of complexity rules changes that. You can enforce 12 characters, symbols, rotation policies, and breach checks. If a user reuses that password on another platform that gets compromised, your login becomes a target. That is the structural weakness behind credential stuffing.
Even breach detection tools that block known leaked passwords are reactive. They work only after exposure is documented and added to a database. Attackers often exploit fresh breach data before it becomes widely indexed.
Multi-factor authentication improves credential stuffing protection significantly, but static MFA alone is not a silver bullet. If MFA is optional, attackers will target accounts without it. If MFA relies on SMS, it may still be vulnerable to SIM swap attacks. If MFA is applied universally without risk awareness, user friction increases.
This is why modern credential stuffing defense integrates adaptive authentication. Risk scoring determines when to challenge users. Low-risk sessions remain seamless. Suspicious logins trigger stronger verification methods such as phishing-resistant MFA or passkeys.
Passwordless authentication further reduces attack surface. When credentials are device-bound and cryptographically verified, stolen password lists lose value. Bots cannot replay what does not exist.
Preventing credential stuffing ultimately requires reducing reliance on reusable shared secrets. As long as passwords are reused across services, credential replay remains viable.
Passwords are not disappearing overnight. But treating them as the sole line of defense is no longer realistic.
Credential stuffing attack prevention improves dramatically when authentication evolves beyond static credentials and becomes context-aware and device-aware.
How LoginRadius Strengthens Credential Stuffing Defense
Credential stuffing defense requires coordination across signals. This is where identity platforms must move beyond basic authentication and into risk-aware orchestration.
LoginRadius integrates intelligent rate limiting directly at the authentication layer. Instead of static thresholds, login attempts are evaluated using contextual velocity analysis across IP, device, and account dimensions. Distributed attacks that bypass simple IP limits become visible through correlated patterns.
Device fingerprinting adds another layer of credential stuffing protection. Browser entropy, automation detection signals, and device reputation scoring help distinguish legitimate users from bot frameworks attempting credential replay. Even when attackers rotate IPs, device traits provide continuity for detection.
Centralized Authentication Surfaces (SSO): LoginRadius leverages Single Sign-On (SSO) architectures to drastically reduce your enterprise attack surface. By minimizing the number of disparate public login portals across your applications, your security operations team only has to guard a single unified control plane, giving bots fewer entry points to test stolen credentials.
IP intelligence is continuously evaluated during authentication. Proxy detection, ASN classification, and geolocation anomaly analysis feed into real-time risk scoring. This allows the system to elevate scrutiny when login attempts originate from suspicious networks without indiscriminately blocking shared residential traffic.
Adaptive MFA strengthens credential stuffing mitigation by applying friction proportionally. Low-risk sessions proceed seamlessly. Elevated-risk attempts trigger step-up authentication using stronger factors such as WebAuthn or biometric-backed verification. This approach balances security with user experience.
Risk-based authentication ensures that credential stuffing attack prevention is not limited to login velocity alone. Behavioral signals, device history, and network context collectively inform access decisions.
Post-authentication monitoring further reduces account takeover risk. Unusual changes in profile data, password resets, or transaction behavior after login can trigger automated safeguards, limiting impact even if credential replay initially succeeds.
Credential stuffing defense is most effective when integrated into the identity control plane rather than bolted on as an external filter. LoginRadius aligns authentication, device intelligence, IP analysis, and adaptive controls within a unified CIAM framework.
Preventing credential stuffing at scale requires orchestration, not isolated features. Identity becomes the enforcement layer, not just the gateway.
The Future of Credential Stuffing: AI vs AI
Credential stuffing attacks are evolving. Automation frameworks are becoming smarter, more adaptive, and increasingly powered by AI. Bots can now simulate mouse movement, randomize typing cadence, and adjust request timing dynamically to evade detection.
This means static rule-based defenses will continue to degrade over time.
Attackers are already using machine learning models to test which login endpoints apply strict rate limits, which deploy weak bot detection, and which rely solely on CAPTCHA. They optimize against predictable defenses.
The next phase of credential stuffing defense will rely heavily on behavioral AI models that analyze micro-patterns in authentication flows. Subtle deviations in request sequencing, device rendering inconsistencies, and cross-session behavioral anomalies will become stronger detection signals than volume-based metrics.
Device-bound authentication will also play a larger role. Passkeys and cryptographic login methods reduce the value of stolen credentials because there is no reusable secret to replay. When authentication becomes bound to a specific hardware-backed key, credential stuffing becomes structurally ineffective.
Zero-trust login models will continue to mature. Every login attempt will be evaluated as a new risk event, regardless of historical trust. Continuous authentication, rather than one-time validation, will define secure access.
Credential stuffing mitigation will increasingly operate in real time with AI-driven correlation across billions of login events. Defense systems will adapt as quickly as attack systems.
The question is not whether credential stuffing attacks will become more sophisticated. They will. The real question is whether login systems evolve into intelligent, risk-aware identity layers or remain static forms guarded by outdated rules.
In the long term, preventing credential stuffing depends less on blocking bots and more on redesigning authentication so that replaying stolen credentials is no longer a viable strategy.
Conclusion
Credential stuffing is not a rare security event. It is continuous background traffic against every exposed authentication endpoint.
Attackers are not trying to break your encryption or reverse-engineer your backend. They are exploiting password reuse and automation at scale. The login form itself becomes the attack surface.
Basic defenses are no longer sufficient. Static rate limits, simple CAPTCHA challenges, and IP blocking address outdated attack models. Modern credential stuffing defense requires layered intelligence velocity analysis, device signals, IP reputation, adaptive authentication, and post-login monitoring working together.
Preventing credential stuffing does not mean eliminating every attempt. That is unrealistic. It means ensuring automated credential replay cannot scale into account takeover.
Organizations that treat login as a dynamic risk decision point rather than a static password check significantly reduce exposure. Identity becomes an active security layer instead of a passive gateway.
The choice is straightforward. Either evolve authentication into a risk-aware control plane, or continue relying on controls that attackers already know how to bypass. If your login is public, it is already being tested.
The only question left is whether your credential stuffing protection is intelligent enough to respond. Start building a login architecture designed for modern bot attacks.
Explore how LoginRadius helps prevent credential stuffing attacks and secure authentication at scale.
FAQs
Q: What is credential stuffing?
A: Credential stuffing is an automated attack where bots use stolen username and password pairs from past data breaches to attempt login on other websites. It works because many users reuse passwords across platforms.
Q: How to detect credential stuffing?
A: You can detect credential stuffing by monitoring distributed login failures, abnormal velocity across multiple accounts, similar device fingerprints across IPs, and unusual geolocation patterns during authentication attempts.
Q: How to prevent credential stuffing attack attempts?
A: Preventing credential stuffing requires layered controls such as intelligent rate limiting, device fingerprinting, IP intelligence, and adaptive MFA. No single control is sufficient on its own.
Q: Is rate limiting enough for credential stuffing mitigation?
A: No. Basic rate limiting only slows down single-source attacks. Modern credential stuffing attacks rotate IPs and distribute attempts, so defense must include device signals, behavioral analysis, and risk-based authentication.



