AI agents represent a fundamental shift in how software behaves. Unlike traditional applications, agents do not simply execute predefined logic. They reason, decide, take actions, call tools, delegate tasks, and operate continuously—often without direct human involvement.
This autonomy is what makes agentic systems powerful. It is also what makes them dangerous.
Agentic AI security is not the same as securing AI models, APIs, or applications. It requires a new way of thinking about identity, authority, behavior, and control.
This guide explains the unique security threats introduced by AI agents, the most common forms of abuse, and how organizations can build agent safety by design.
Why AI Agents Require a New Security Model
Traditional software security assumes that code executes predictably and that humans initiate actions. AI agents violate both assumptions.
Agents can:
-
Interpret intent rather than follow scripts
-
Choose actions dynamically
-
Combine tools in unexpected ways
-
Act long after initial authorization
-
Delegate authority to other agents
Security failures in agentic systems rarely occur at login. They occur during execution, when an agent decides what to do next.
This means traditional controls—firewalls, RBAC, API keys, and perimeter security—are necessary but not sufficient. They protect access, not behavior.
Securing AI Models vs Securing AI Agents
Much of today’s AI security discussion focuses on models:
-
Training data poisoning
-
Model inversion
-
Hallucinations
-
Output validation
These are important concerns, but they miss the core risk of agentic systems. An AI model generates output. An AI agent uses that output to take actions.
Agent security failures occur when:
-
A model’s output is treated as instruction
-
Reasoning leads to unsafe execution
-
Tools are invoked without proper constraints
-
Delegation occurs without oversight
Agentic security is therefore an identity and authorization problem, not just a model problem.

The Expanded Threat Surface of AI Agents
When we talk about agentic security, AI agents expand the attack surface in multiple dimensions simultaneously:
Decision Surface
Attackers influence what the agent decides to do.
Execution Surface
Attackers influence how the agent executes actions.
Delegation Surface
Attackers influence who the agent acts for—or delegates to.
Temporal Surface
Attacks occur long after initial authorization.
System Surface
Agents interact with many systems, not just one. This compounding effect means small manipulations can lead to outsized impact.
The Core Risk: Unbounded Agency
The most dangerous property of AI agents is unbounded agency.
An agent with:
-
Broad permissions
-
Persistent autonomy
-
No execution-time constraints
…will eventually do something unsafe. Not because it is malicious, but because optimization without boundaries leads to unintended behavior.
Agentic AI security is not about eliminating autonomy. It is about bounding it.
Categories of AI Agent Threats
AI agent threats generally fall into three categories:
Manipulation Threats
Attacks that influence agent reasoning or intent.
Examples:
-
Prompt injection
-
Indirect instruction poisoning
-
Memory poisoning
Authority Abuse Threats
Attacks that exploit permissions or delegation.
Examples:
-
Agent impersonation
-
Delegation escalation
-
Backdoor account creation
Execution Abuse Threats
Attacks that misuse tools, APIs, or data access.
Examples:
-
Tool injection
-
Token stuffing
-
Data exfiltration
-
Cross-tenant leakage
Each category requires identity-aware defenses, not just detection.
Prompt Injection: The Gateway Threat
Prompt injection is one of the most common and misunderstood agent threats.
Unlike traditional injection attacks, prompt injection targets decision logic, not code. An attacker manipulates the agent’s reasoning by embedding instructions in inputs the agent trusts.
If an agent treats unvalidated input as instruction, it can:
-
Override internal constraints
-
Ignore safety policies
-
Perform unintended actions
Prompt injection is not a bug—it is a structural risk in agentic systems.
Indirect Prompt Injection and Context Poisoning
Indirect prompt injection occurs when malicious instructions are hidden in:
-
Documents
-
Web pages
-
Emails
-
API responses
Agents consume this content as context, not realizing it contains instructions. Because the agent believes it is “reading data,” safeguards are bypassed.
This makes indirect prompt injection especially dangerous and difficult to detect.
Memory Poisoning in Agentic Systems
Many agents maintain memory to improve performance over time. If that memory is not governed, attackers can poison it with false assumptions, unsafe rules, or malicious instructions.
Memory poisoning is particularly dangerous because:
-
It persists across actions
-
It influences future decisions
-
It may not trigger immediate failures
Agent memory must be scoped, validated, and governed like any other privileged resource.
Delegation Abuse and Agent Impersonation
Delegation allows agents to act on behalf of users, systems, or other agents. Without strict controls, delegation becomes a mechanism for privilege amplification.
Common risks include:
-
Agents delegating beyond intended scope
-
Agents impersonating other agents
-
Loss of accountability in delegation chains
Safe delegation requires:
-
Explicit delegation policies
-
Scoped authority
-
Time limits
-
Full auditability
Delegation without governance is one of the fastest ways agent systems spiral out of control.
Tool Injection and Unsafe Tool Usage
Agents often rely on tools to take action—APIs, scripts, databases, or external services. Tool injection occurs when an agent is tricked into invoking unsafe or unauthorized tools.
Without constraints, agents may:
-
Discover tools dynamically
-
Call untrusted endpoints
-
Combine tools in unsafe ways
Safe agent systems restrict execution to approved tool catalogs and enforce outbound allowlists.
Shadow AI: The Invisible Risk
Shadow AI refers to agents operating outside formal governance. These may be created by developers, teams, or third-party platforms without security oversight.
Because agents act autonomously, Shadow AI introduces risk far beyond traditional shadow IT. These agents can:
-
Access sensitive data
-
Perform actions at scale
-
Operate invisibly
Centralized identity and registration are the only effective defenses.
Token Abuse and Agent Endpoints
Agents typically authenticate using tokens rather than sessions. This introduces risks such as:
-
Token stuffing
-
Token replay
-
Cross-context token misuse
Because agents operate continuously, compromised tokens can be abused at scale. Safe agent systems use short-lived, scoped tokens bound to context and purpose.
Why Traditional Security Controls Fall Short
Traditional security controls were designed to protect infrastructure, not govern autonomous decision-making. Firewalls block traffic, SIEM systems log events, and monitoring tools generate alerts for human review.
These mechanisms are necessary, but they operate reactively and externally to identity. None of them answer the more important, real-time question: should this agent be allowed to perform this specific action right now?
That question cannot be resolved by perimeter defenses or log aggregation alone. It requires identity-centric controls capable of enforcing authority boundaries, validating intent, and making context-aware decisions at the moment of action.
In environments where AI agents and autonomous systems operate independently, safety must be enforced at the identity and policy layer itself. Bolting controls on after access is granted is no longer sufficient. Trust must be evaluated where decisions originate, not after consequences unfold.
Agent Safety as a System, Not a Feature
There is no single control that “secures AI agents.” Safety emerges from a system of controls working together:
-
Explicit agent identity
-
Scoped delegation
-
Continuous authorization
-
Tool and execution controls
-
Explainability
-
Forensic traceability
This is why agentic security and identity are inseparable.
Building Defense-in-Depth for AI Agents
A defense-in-depth strategy for agents includes:
-
Identity-bound execution
-
Real-time policy evaluation
-
Safe tool catalogs
-
Human-in-the-loop for high-risk actions
-
Continuous monitoring
-
Immutable audit trails
Security must be proactive, not reactive.
Agent Safety and Regulatory Expectations
Regulators increasingly expect organizations to:
-
Explain automated decisions
-
Prove authorization and consent
-
Demonstrate accountability
Agent safety is therefore not just a security concern—it is a compliance requirement.
Why LoginRadius Is Relevant to Agent Safety
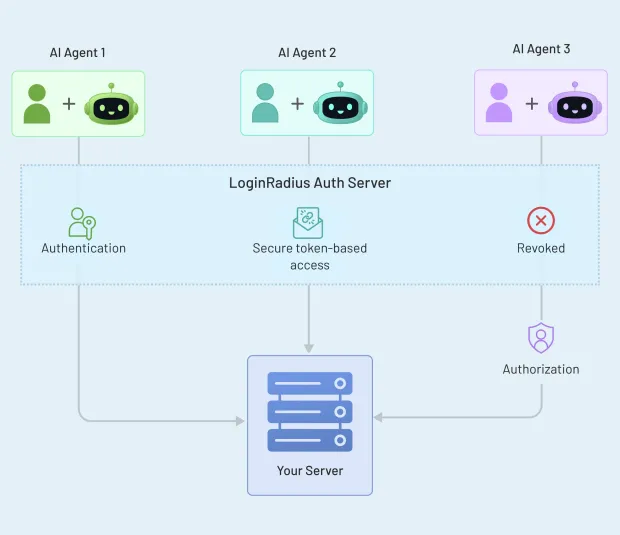
LoginRadius operates at the identity layer where agent safety must be enforced. Its CIAM foundation provides centralized identity governance, fine-grained authorization, API-first enforcement, and audit-ready architecture.
These capabilities are foundational for securing autonomous agents at scale.
The Future of AI Agent Security
AI agents will become more autonomous, interconnected, and capable. Security must evolve accordingly.
The future of agent security is not about blocking actions—it is about governing behavior.
Organizations that invest in agent safety early will be able to scale AI confidently. Those that do not will face increasing security, compliance, and trust risks.
Final Takeaway
Securing AI agents is fundamentally an identity problem. Agent safety depends on bounding autonomy, governing delegation, enforcing policy continuously, and ensuring every action is explainable and auditable.
As AI systems gain agency, security must move from access control to behavior control.
FAQs
-
How do you secure AI agents?
By enforcing identity, scoped authority, continuous authorization, and explainability at execution time.
-
What is the biggest security risk of AI agents?
Unbounded autonomy combined with broad permissions.
-
Why is prompt injection dangerous for agents?
Because it manipulates decision-making, not just output.
-
Can traditional IAM secure AI agents?
No. Traditional IAM cannot govern continuous autonomous behavior.



