We'll talk about Apache Beam in this guide and discuss its fundamental concepts. We will begin by showing the features and advantages of using Apache Beam, and then we will cover basic concepts and terminologies.
Ever since the concept of big data got introduced to the programming world, a lot of different technologies, frameworks have emerged. The processing of data can be categorized into two different paradigms. One is Batch Processing, and the other is Stream Processing.
Different technologies came into existence for different paradigms, solving various big data world problems, for, e.g., Apache Spark, Apache Flink, Apache Storm, etc.
As a developer or a business, it's always challenging to maintain different tech stacks and technologies. Hence, Apache Beam to the rescue!

What is Apache Beam?
Apache Beam is an open source, centralised model for describing parallel-processing pipelines for both batch and streaming data. The programming model of the Apache Beam simplifies large-scale data processing dynamics.
The Apache Beam model offers helpful abstractions that insulate you from distributed processing information at low levels, such as managing individual staff, exchanging databases, and other activities. These low-level information are handled entirely by Dataflow.
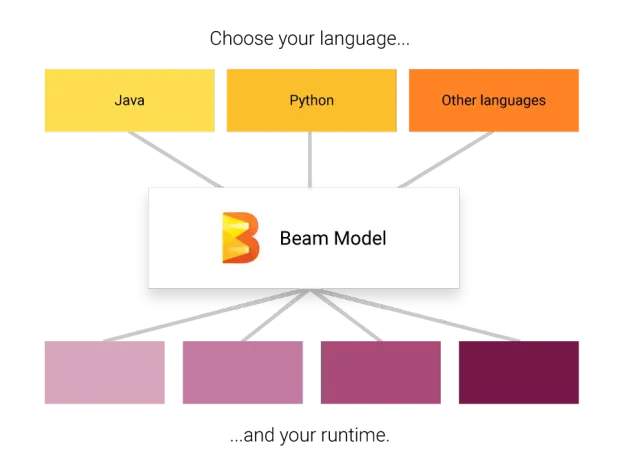
Features of Apache Beam
The unique features of Apache beam are as follows:
- Unified - Use a single programming model for both batch and streaming use cases.
- Portable - Execute pipelines in multiple execution environments. Here, execution environments mean different runners. Ex. Spark Runner, Dataflow Runner, etc
- Extensible - Write custom SDKs, IO connectors, and transformation libraries.
Apache Beam SDKs and Runners
As of today, there are 3 Apache beam programming SDKs
- Java
- Python
- Golang
Beam Runners translate the beam pipeline to the API compatible backend processing of your choice. Beam currently supports runners that work with the following backends.
- Apache Spark
- Apache Flink
- Apache Samza
- Google Cloud Dataflow
- Hazelcast Jet
- Twister2
Direct Runner to run on the host machine, which is used for testing purposes.
Basic Concepts in Apache Beam
Apache Beam has three main abstractions. They are
- Pipeline
- PCollection
- PTransform

Pipeline:
A pipeline is the first abstraction to be created. It holds the complete data processing job from start to finish, including reading data, manipulating data, and writing data to a sink. Every pipeline takes in options/parameters that indicate where and how to run.
PCollection:
A pcollection is an abstraction of distributed data. A pcollection can be bounded, i.e., finite data, or unbounded, i.e., infinite data. The initial pcollection is created by reading data from the source. From then on, pcollections are the source and sink of every step in the pipeline.
Transform:
A transform is a data processing operation. A transform is applied on one or more pcollections. Complex transforms have other transform nested within them. Every transform has a generic apply method where the logic of the transform sits in.
Example of Pipeline
Here, let's write a pipeline to output all the jsons where the name starts with a vowel.
Let's take a sample input. Name the file as input.json
1{"name":"abhi", "score":12}
2{"name":"virat", "score":23}
3{"name":"dhoni", "score":45}
4{"name":"rahul", "score": 156}
5{"name": "Edmund"}
6{"name": "Ojha"}The input should be a newline delimited JSON.
Include the following dependencies in your pom.xml
1<dependency>
2 <groupId>org.apache.beam</groupId>
3 <artifactId>beam-sdks-java-core</artifactId>
4 <version>2.24.0</version>
5</dependency>
6<dependency>
7<groupId>org.apache.beam</groupId>
8<artifactId>beam-runners-direct-java</artifactId>
9<version>2.24.0</version>
10</dependency>Let's code the beam pipeline. Follow the steps
-
Create a pipeline.
1Pipeline pipeLine = Pipeline.create(); 2 // OR 3 // Pipeline pipeLine = Pipeline.create(options);Create a pipeline which binds all the pcollections and transforms. Optionally you can pass the PipelineOptions
optionsif needed. -
Read the input file
1PCollection<String> inputCollection = pipeLine.apply("Read My File", TextIO.read().from("input.json"));Use the
TextIOtransform to read the input files. Every line is a different json record. -
Apply a transform to filter out the names starting from a vowel
1PCollection filteredCollection = inputCollection.apply("Filter names starting with vowels", Filter.by(new SerializableFunction<String, Boolean>() { 2 public Boolean apply(String input) { 3 ObjectMapper jacksonObjMapper = new ObjectMapper(); 4 try { 5 JsonNode jsonNode = jacksonObjMapper.readTree(input); 6 String name = jsonNode.get("name").textValue(); 7 return vowels.contains(name.substring(0,1).toLowerCase()); 8 } catch (JsonProcessingException e) { 9 e.printStackTrace(); 10 } 11 return false; 12 } 13}))The filter transform takes a SerializableFunction Object where the
applymethod is overridden. Every json-string record is converted to a JSON. The first character of thenameis checked if it's a vowel. The transform is applied to each input JSON record. Based on the boolean value returned, the record is retained or discarded. -
Write the results to a file
1inputCollection.apply("write to file", TextIO.write().to("result").withSuffix(".txt").withoutSharding());The results of the
Filtertransform are stored in a text file using the write method of theTextIOtransform. As PCollections are distributed across machines, the results are written to multiple files/shards. To avoid this, we usewithoutShardingwhere all the output is written to a single file.
Output:
1{"name": "Edmund"}
2{"name": "Ojha"}
3{"name":"abhi", "score":12}Complete Code:
1Pipeline pipeLine = Pipeline.create();
2final Set<String> vowels = new HashSet<String>(Arrays.asList("a","e","i","o","u"));
3pipeLine.apply("Read My File",
4TextIO.read().from("input.json"))
5.apply("Filter names starting with vowels", Filter.by(new SerializableFunction<String, Boolean>() {
6 public Boolean apply(String input) {
7 ObjectMapper jacksonObjMapper = new ObjectMapper();
8 try {
9 JsonNode jsonNode = jacksonObjMapper.readTree(input);
10 String name = jsonNode.get("name").textValue();
11 return vowels.contains(name.substring(0,1).toLowerCase());
12 } catch (JsonProcessingException e) {
13 e.printStackTrace();
14 }
15 return false;
16 }
17 }))
18 .apply("write to file", TextIO.write().to("result").withSuffix(".txt").withoutSharding());
19
20pipeLine.run().waitUntilFinish();For more advanced concepts, refer to the official site - beam.apache.org


